Connect to Any REST API Using Action Rivers: An Example Use Case
- 3 Minutes to read
- Print
- DarkLight
- PDF
Connect to Any REST API Using Action Rivers: An Example Use Case
- 3 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Introduction
This document provides a step-by-step guide on utilizing Rivery's Action River feature to establish a connection with any REST endpoint and incorporate it as a new data source. While Rivery frequently includes built-in support for various data sources, there might be situations where the specific data source you require isn't included in Rivery's list of supported options. In such cases, this document can be useful and help you avoid unnecessary coding.
This document will illustrate the procedure for establishing a connection to an API endpoint using the GET method to fetch a user list. Every stage of the process is thoroughly covered and explained through a video tutorial provided at the conclusion of this guide.
Authentication
To create a connection to an API, the user needs to provide the API URL. If the user is creating a Source, they will make a GET call to the API.
A username and password, OAuth2, or Multi-Bearer authentication can all be used for authentication.
This API endpoint is a public endpoint, so authentication is not required.
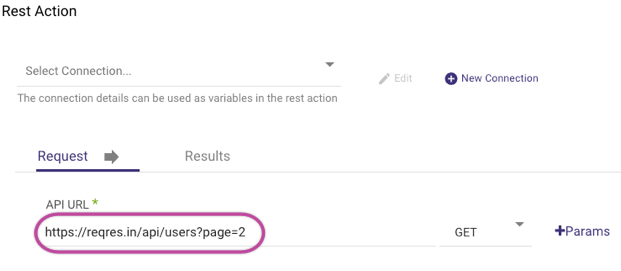
Testing the Connection
In this example, the user has access to an API endpoint that returns a list of users. By selecting the "Test REST Action" button, the user can verify the connection. This action provides a success code of 200 (connection succeeded) and a sample dataset.
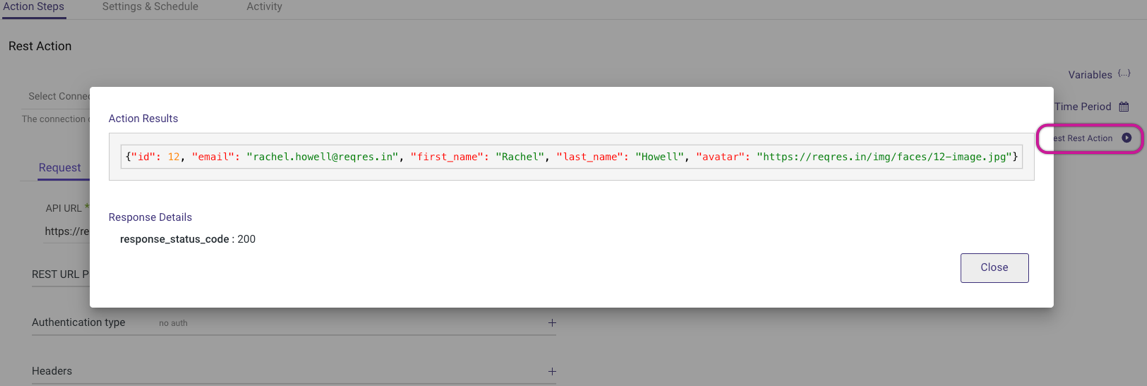
Request and Results Menu
When working with a REST API, these common options found in the Request and Results menus may come in handy:
- Adding Parameters
- Pagination Methods
- Sending a request in a loop.
Adding Parameters
Additional parameters, such as a last modified date, can be added to filter the retrieved data. For example, specifying a last modified date of one day will retrieve only the users who were added or modified within the past day.
Please Note:
It is restricted to employ the same parameter multiple times.
When the "Add" button is clicked under "REST URL Params," the specified parameter will automatically be appended to the URL, eliminating the need for manual inclusion.
This process is not visible to the user, but behind the scenes, the parameter is added to the URL in the following format:https://reqres.in/api/users?last_mod_date={time_range.start_date}
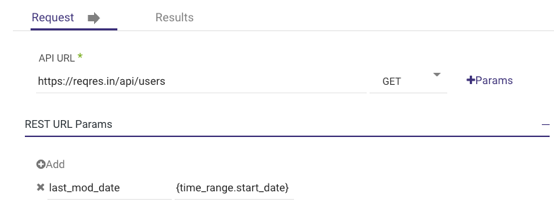
If you name the parameter Key, it is important to avoid using the same name in the Value field. If, for instance, the name "StartDate" is used in the Key field and the same name is used in the Value field {StartDate}, the parameter will not be appended.

Pagination Methods
To handle large data sets, Rivery provides pagination methods that allow users to retrieve and process data in smaller chunks.
There are several pagination methods available in Rivery, including:
- Pagination by Offset
- Pagination by Page
- Next Page in Response.
The specific method used will depend on the data source and the requirements of the integration or transformation task. For further details, see our Pagination Options article.
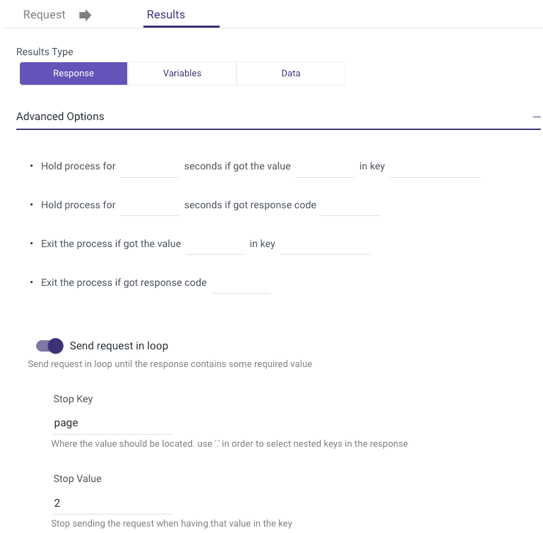
Sending a Request in a Loop
Rivery enables to set up a loop that repeatedly runs a request until a certain stop value is reached. This can be useful for situations where data is being constantly updated and needs to be periodically retrieved and processed.
Creating a Custom Connector
Once a connection to a REST endpoint has been established, it can be saved as a custom connector using the REST API Source. To do this, create a new Source to Target River, select the REST API Source you just created, and then proceed to configure your Target in the same way you would for any other Source to Target River.

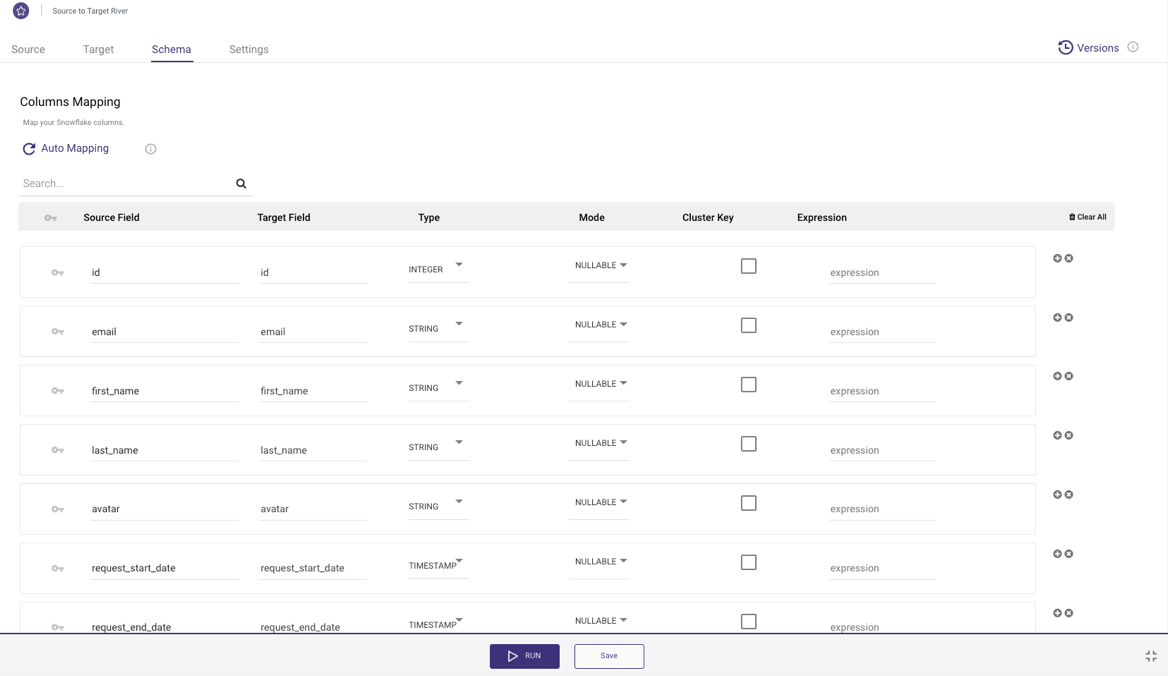
Automating Table Structure Mapping
In this case, the user chooses a Source to Target River and select the REST API as the Source and Snowflake as the Target. Now, Rivery handles the task of using the JSON payload from the API endpoint to define the target schema. The user can easily use the "Auto Mapping" button and Rivery will automatically map the table structure and data types based on the metadata retrieved from a sample test.
Ingesting Data
After the table structure has been generated, data can be ingested by running the River. Data will be retrieved from the API based on the specified parameters (such as last modified date) and pushed into the target (in this case, Snowflake) using the specified primary key for merging.
Video
Here is a video guide for this particular use case:
Was this article helpful?