Google Sheets Walkthrough
- 2 Minutes to read
- Print
- DarkLight
- PDF
Google Sheets Walkthrough
- 2 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
A Guide for getting data from Google Sheets to Rivery.
Prerequisites
How to pull data from Google Sheets using Rivery
First, select 'Create New River' from the top right of the Rivery screen.
)
Choose 'Data Source to Target' as your river type.
In the 'General Info' tab, name your river, describe it, and choose a group.
Next, navigate to the 'Source' tab.
Find Google Sheets in the list of data sources and select it. (under Organization)
)
Under Source Connection, select the connection you created, or create a new one.
Now, please input the GUID of the single file you'd like to retrieve data from (compatible with shared files).
Note:
This ID is the value between the "/d/" and the "/edit" in the URL of your spreadsheet. For example, consider the following URL that references a Google Sheets spreadsheet: docs.google.com/spreadsheets/d/1qpyC0XzvTcKT6EISywvqESX3A0MwQoFDE8p-Bll4hps/edit#gid=0 The ID of this spreadsheet is 1qpyC0XzvTcKT6EISywvqESX3A0MwQoFDE8p-Bll4hps
There are two ways to extract data:
- All
- Incremental load by file modified timestamp
If you choose All enter the following parameters:
- Type in a null representative word (e.g., null).
- Skip to step 1.
If you choose Incremental enter the following parameters:
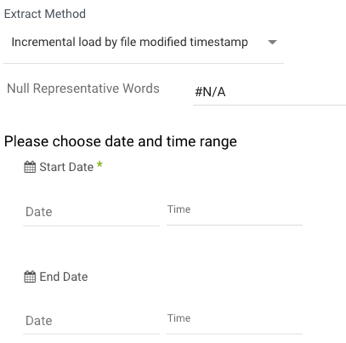
- Choose a Date Range and Time period. Here's an example:
Note:
- Start Date is mandatory.
- Data can be retrieved for the date range specified between the start and end dates.
- If you leave the end date blank, the data will be pulled at the current time of the river's run.
- Dates timezone: UTC time.
- The Start Date won't be advanced if a River run is unsuccessful.
If you don't want this default setting, click More Options and check the box to advance the start date even if the River run is unsuccessful (Not recommended).

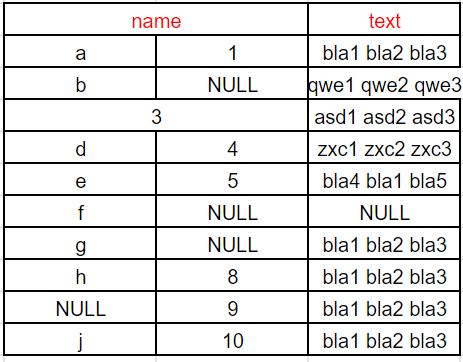
- Select merged headers if they exist.
- If multiple columns have a joint header (merged cells) than the leftmost cell will be passed on to the target even if it's empty.
- Example starting from this Google spreadsheet:
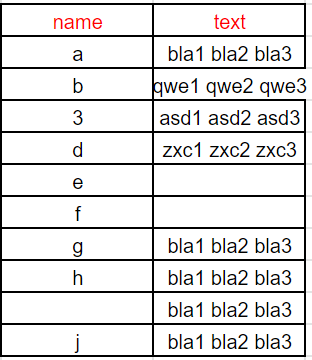
- The result merged table in the target will be:
- Specify whether the sheet has a header. In case there is a header specify its position.
- Set the sheet's columns by name or position number (e.g., 1,2,3).
- For multiple sheets, separate them with commas. Leave empty to include all.
- According to name:
- According to position:
)
)
Optional: define file manipulations.
Source Auto Mapping
The last step in the source page is the Auto Mapping feature.
Rivery will automatically set your mapping based on the data returned from the sheets you've selected.
You may also modify the generated fields according to:
- Choose which fields you want to fetch in the Mapping table, and add fields on your own, or remove unwanted fields.
- Check the "fill empty" box if you want empty cells to get values from the above closest cell.
- Define each field as a source or static. The source is a field coming from your Google Sheet and static is a field for adding expression as you would like.
- Static will just put a repeated value in each cell in the respective field alias.
- The source will do a regex comparison to the field name. Several examples of such expressions (remove quotations; " "):
- the expression: ".*?\d+" will take copy all values in a given cell up to the first digit. ('id123' -> 'id1')
- the expression: "\w+ \w+" will take the first 2 words. ('first second third' -> 'first second')
- Other types of expressions in Python's re.match can be found in here: https://docs.python.org/2/library/re.html
)
Warnings:
- Defining an existing source field will erase its previous source. In case you erased a source field by setting it as static, and want to restore it back, you need to add it manually or press "clear all" and then start auto mapping again.
- The expressions may contain strings or functions which Google Sheets supports.
Was this article helpful?