MongoDB Change Streams Overview
- 3 Minutes to read
- Print
- DarkLight
- PDF
MongoDB Change Streams Overview
- 3 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
What is Change Streams Extraction?
Rivery's Log-Based extraction mode provides a real-time stream of any changes made to the databases and tables configured, eliminating the need to implement and maintain incremental fields or retrieve data via select queries. It also allows you to retrieve schema changes from the database.
How Does Change Streams Extraction Work?
Rivery uses the Change Data Capture architecture to continuously pull new rows from the Change Streams in order to retrieve data.
Change Streams is a fast and effective method of continuously fetching data from databases using the database transaction log.
Rivery uses the Overwrite loading mode to take a full snapshot (or migration) of the chosen table(s) in order to align the data and metadata as it was on the first run. Rivery takes the existing 'Change Stream' records and performs an Upsert-Merge to the target table(s) after the migration is complete, while continuing to fetch new records from the log as they are created.
Rivery's MongoDB connection reads the 'Change Stream' records and generates change events in the FileZone files for row-level INSERT and UPDATE commands. Each file represents a set of database actions performed over a period of time. The data from the log is continuously streamed into the FileZone path established in the River and pushed into the target by the River's scheduled frequency. This method saves the data first in the FileZone, and then it may be pushed into the target DWH at any moment.
FileZone is covered in further detail in the Target documentation.
For further information about Change Streams Metadata Fields, please refer to our Database Overview document.
CDC Point in Time Position Feature
The CDC “Point in Time” Position feature allows users to gain deeper insights into the operational details of a River's streaming process. This functionality is essential for data recovery and synchronization, enabling users to locate and retrieve data from a specific point in history using the exact information stored in the CDC log position. For additional information, refer to our documentation.

How to Enable Change Streams Extraction?
After you've established a connection, go to the Source tab and do the following:
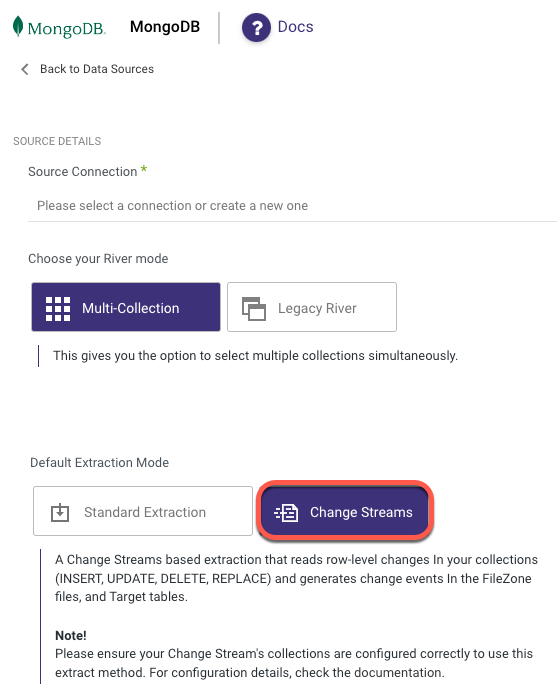
Choose the Multi-Collection as the River mode.
select the Change Streams as the extraction mode.
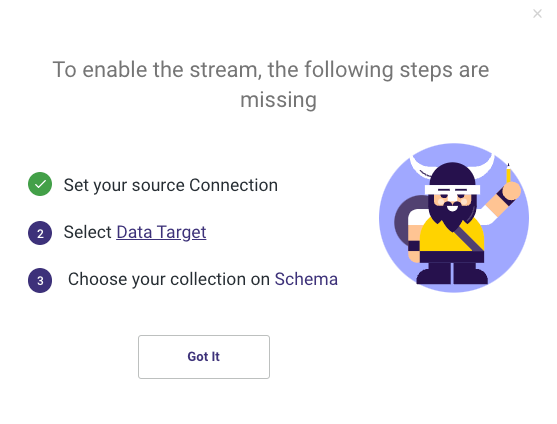
A brief reminder appears, encouraging you to check your connection and set up your Source and Target, which will happen next. Select 'Got It' to proceed.
Turn the 'Enable Stream' toggle to true at the bottom of the page.
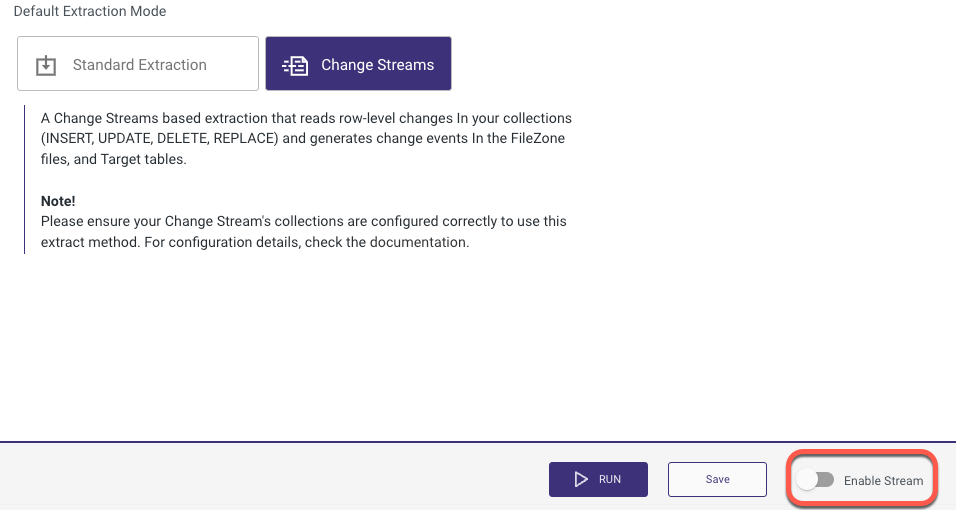
A new window pops up, guiding you on the following steps. Select 'Target'.
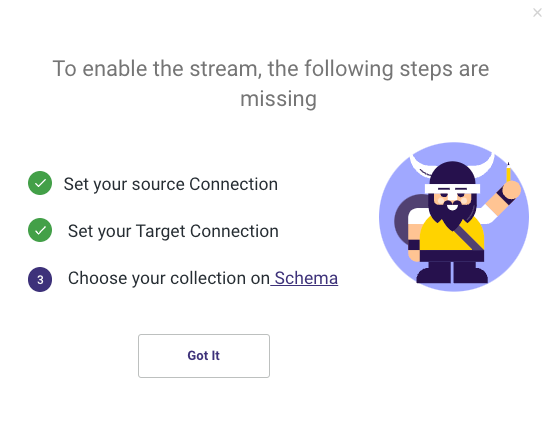
You'll be directly sent to the Target tab, where you can choose your data target.
Define your Target Connection, then choose a Database and a Schema to load into.
To make sure the operation is complete, click the Enable Log toggle once more.
To navigate to the Collections, click the Schema tab.
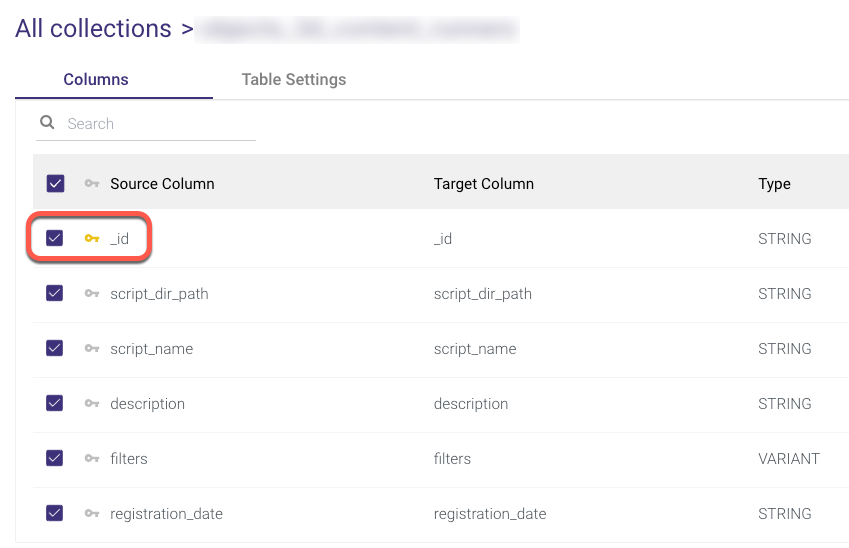
A minimum of one Collection must be chosen.
To use CDC, the table must contain a key, which is defined as the Source Column _id.
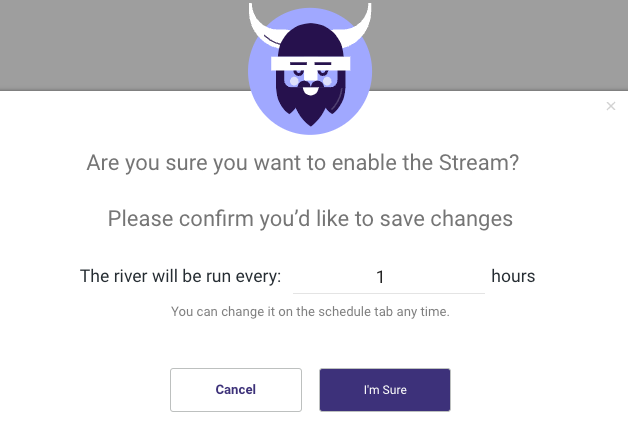
Navigate to the 'Enable Stream' toggle and select the number of hours you want to run the River, then click 'I'm Sure'.
Wait for the Initiation Log to complete its processing.
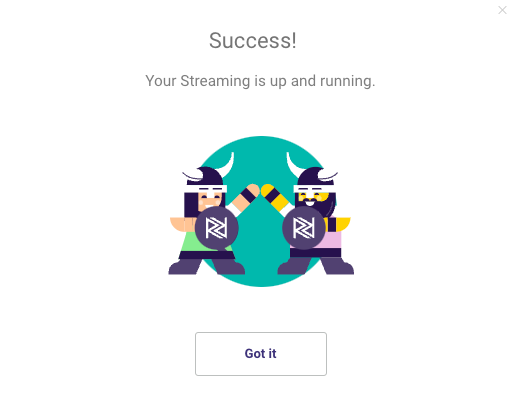
You're all set to run your log-based River now.
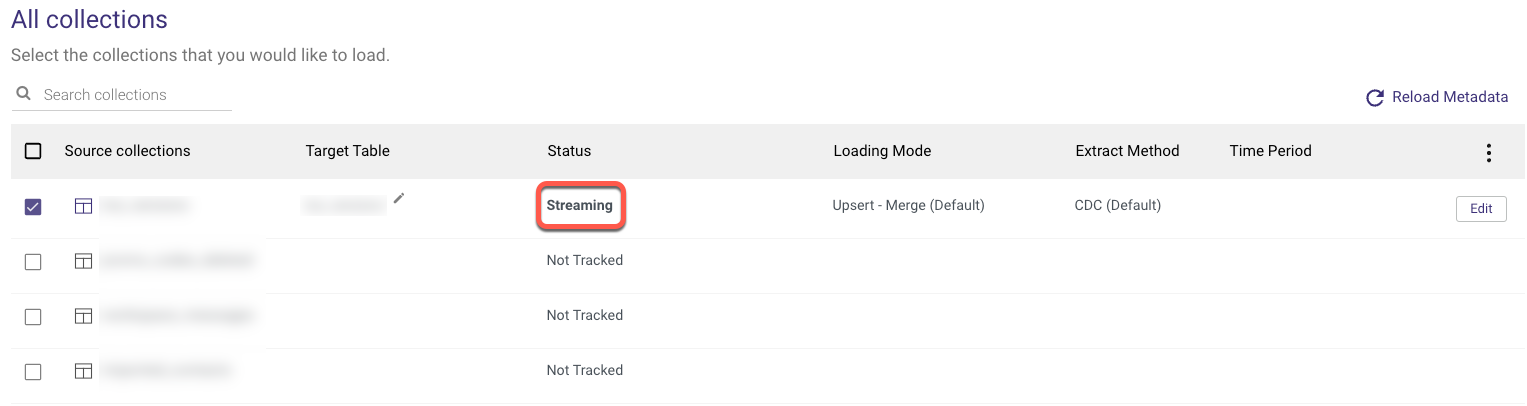
Following the completion of the River Run, return to the Schema tab and check that the Collections you selected are Streaming.
Limitations
Time-series collections do not support Change Streams due to a limitation in MongoDB.
There are some limitations when it comes to connecting to MongoDB (click the URI and SSH to get to their documentation):
If you're using Change Streams with Atlas, leave the analytics node out of the connection URI. You can only connect to the Primary Node with MongoDB Atlas. We'll be able to connect to the Analytics Node, but we won't be able to get any messages from it due to Atlas' implementation. | |
|
MongoDB will not send any documents that are more than 16MB in size, including all metadata in the change stream.
Any special character will be replaced with an underscore. As a result, if you wish to edit the table name, go to:
1. The 'Schema' tab
2. Select a collection
3. Click 'Table Settings'
4. Choose 'Edit' to change the table name manually.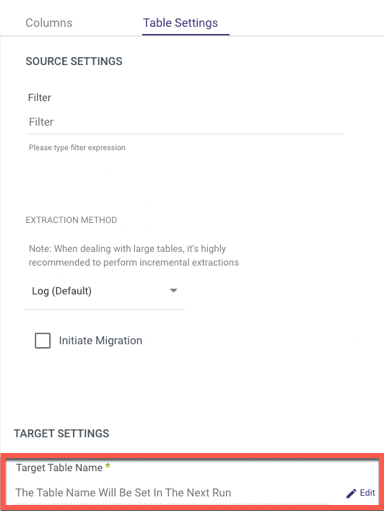
Was this article helpful?