MongoDB Best Practice For Pulling Large Amounts Of Data
- 9 Minutes to read
- Print
- DarkLight
- PDF
MongoDB Best Practice For Pulling Large Amounts Of Data
- 9 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
In historical data migration / large collection(s) cases, there is a need to pull a vast amount of data from MongoDB into any of the optional target DWH availeble in the Rivery console.
This guide will walk you through the best practice and efficient way to connect your MongoDB to Rivery.
Source Configuration
Extract Method:
Best practice suggestion for pulling data from your collection will be to use the “Incremental” extract mode. This mode pulls data by an incremental value that performs as an Index, that is fetching only the data that had been changed since the last run. In the Incremental extract method there are additional options:
Incremental Attributes:
Set the name of the incremental attribute to run by. e.g. UpdateTime.Incremental Type:
Timestamp | Epoch. Choose the type of incremental attribute.Date Range:
- In Timestamp, choose your date increment range to run by.
- In Epoch, choose the value increment range to run by.
- If no End Date / Value is entered, the default is the last date/value in the table. The increment will be managed automatically by Rivery.
Include End Value:
Should the increment process take the end value of the run or not.Interval Chunks:
On what chunks the data will be pulled by. Split the data by minutes, hours, days, months, or years, It is recommended to split your data into chunks in the case of a large amount of returned data to avoid a call timeout from the source side.Dynamic Chunk Size Management
Dynamic chunk size management automatically adjusts data batch sizes based on available system memory, helping to optimize performance and prevent runtime failures during data processing. When enabled, the system ensures that chunk sizes stay within safe memory limits, reducing the risk of out-of-memory errors. Users can also choose to manually set a fixed chunk size; however, if the defined size exceeds memory limitations, the system will block execution and display a clear validation message. This feature is accessible in the UI under the "Max Rows In Batch" setting, where users can choose between "Dynamic" (recommended for large collections) or "Manual" modes.Filter (Optional):
Filter the data that will be pulled. The filter format will be a MongoDB Extended JSON. e.g. {"account":{"ne": true}}. Limit (Optional):
Limit the rows to pull.Auto Mapping: Rivery will determine your table / query metadata. You can choose the set of columns you want to fetch from the source, add a new column that hadn’t got in Rivery determination or leave it as it is. If you don’t make any of Auto Mapping, Rivery will get all of the columns in the table.
Schema Configuration
- Converting Entire Key Data As a STRING (Optional):
In some cases, the data is not as expected by a target, like key names starting with numbers, or flexible and inconsistent object data. A possible option to overcome this will be converting attributes to a STRING format by setting their data types in the mapping section as a STRING.
An example for this can be the following key:value combination -
{
"name": "myname".
"id": 1,
"sites": {"www.google.com": {"count": 3},
"www.yahoo.com": {"count": 4},
"www.amazon.com": {"count": 4}
}
The mapping, in this case, would have the following structure:
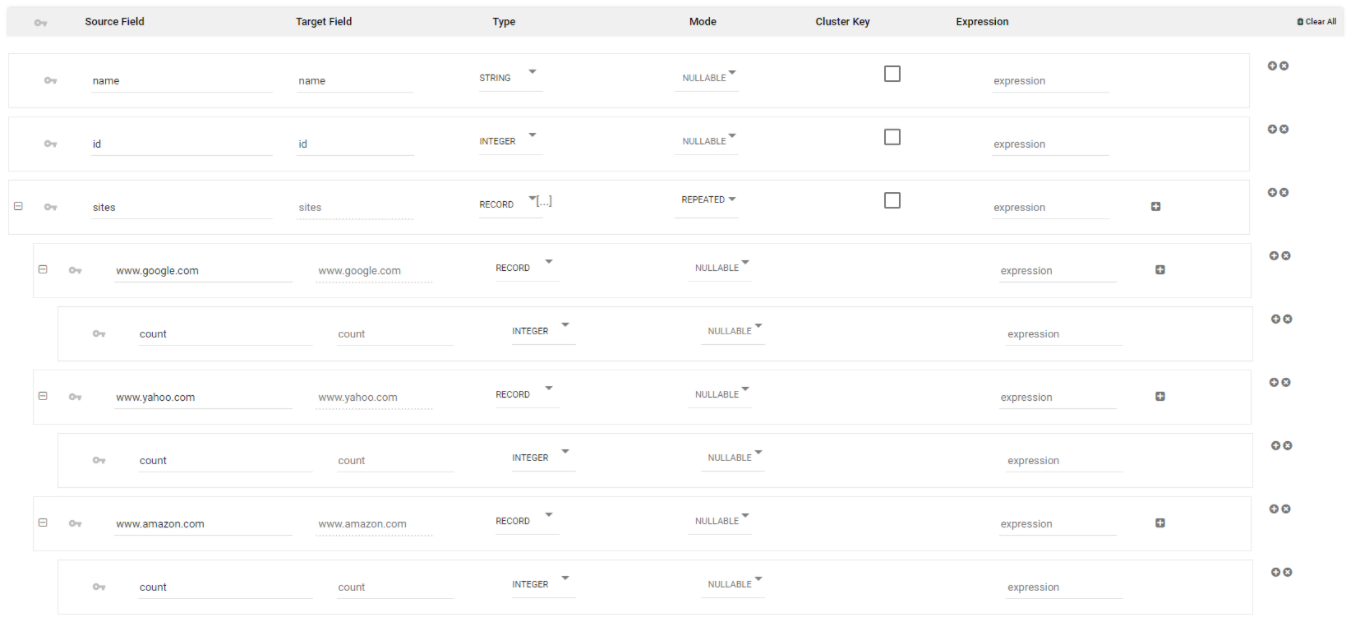
As seen, the site’s key, in this case, has inconsistent changing values, and the values themselves (sites) are being mapped as columns. In order to deal with this situation, the mapping solution will be to define the sites data type to a STRING and parse this column by using an open JSON function on the target’s side:

Note:
Conversion exists for any value under that key.
Arrays and objects will be converted to JSON strings.
Enhancing Data Preservation and Mapping
Only when employing the Legacy River mode and selecting Snowflake as the Target.
Preserve the raw data of the collection exclusively for Snowflake as the target platform. When dealing with JSON objects or arrays that feature schemaless keys, potentially changing per row or including special characters or blanks, Snowflake users can leverage its built-in capability to query complex JSON structures using the Semi-Structured Query Mechanism. It's advised in such scenarios to reclassify the entire column as a VARIANT column and then extract the necessary columns within Snowflake's console or through a Logic river using any of Snowflake's "Open JSON" functions.
To achieve this, activate the "Preserve Raw Data" toggle (located in the Target tab under file settings). This will automatically introduce an Array into the column mapping, which defaults to loading as a variant column. This approach helps maintain the row's granularity.
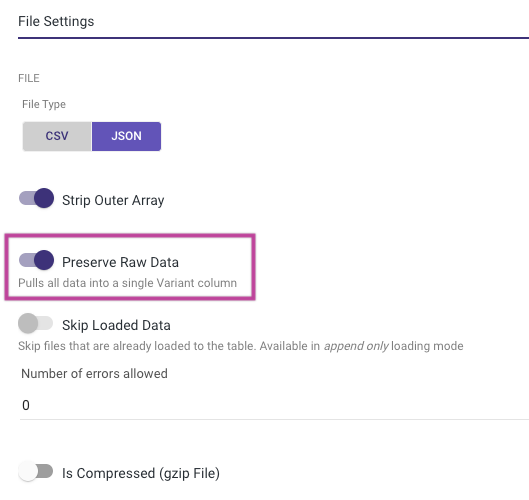
Please Note:
The "Preserve Raw Data" toggle is specifically available in the Legacy River mode; it's not supported in Change Streams.
The mapping outcome appears as shown below:

Additionally, you have the option to utilize the "expression" column mapping feature to extract a specific column from the raw JSON data. This extracted column can function as a key for the Upsert merge loading mode:

Retrieve Large Collections by Chunks and Range Queries
The MongoDB Log Based Mode can pull large collections by breaking them down into chunks. When the number of records in a collection exceeds the maximum number of rows specified in the River to retrieve the data by using a range query with the "_id" index instead of using "skip" for pagination.
This method sorts and increments the data, pulling it in batches using a range query. This technique is more efficient than the traditional method of using "skip" for pagination, especially for large collections, as it avoids the performance overhead associated with the use of "skip".
By breaking down the collection into smaller chunks, the MongoDB Log Based Mode improves the speed and efficiency of data retrieval, making it a more reliable and effective tool for managing large datasets.
For more information on range queries, you can refer to the MongoDB documentation
Retrieve Large Collections by Using Concurrent Requests
To enhance the extraction process of large Collections, consider raising the number of concurrent requests to your MongoDB. This adjustment enables Rivery to retrieve each data chunk concurrently rather than sequentially.
Please Note:
The maximum number of concurrent requests permitted by your MongoDB depends on its memory configurations. Running a River with concurrent requests exceeding the capabilities of your MongoDB can result in River failure.
You can find this option within both Multi-Table and Legacy River modes.
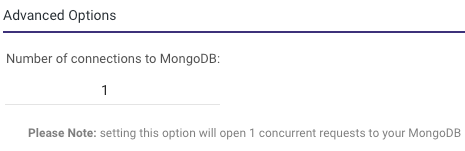
This is a console tour for working with 'Number of Connection in MongoDB'. Please hover over the rippling dots and read the notes attached to follow through:
Indexing Incremented Fields for Performance in MongoDB
When working with MongoDB and incrementing fields, it's crucial to ensure that the incremented field is indexed properly. Failing to do so can lead to significant performance issues, especially when pulling large amounts of data. MongoDB does not automatically index "datetime" columns, so manual intervention is necessary for optimal performance.
Why Index Incremented Fields?
Indexes in MongoDB significantly speed up query performance by allowing the database to locate specific documents more efficiently. When you increment a field without indexing it, MongoDB has to scan through the entire collection to find the relevant documents. This process can be time-consuming and resource-intensive, especially as the collection size grows.
Best Practices for Indexing Incremented Fields
Identify Incremented Fields: Determine which fields in your MongoDB documents are frequently incremented or used in queries involving increments.
Create Indexes: For each identified field, create an index using the createIndex method in MongoDB. Specify the field to be indexed and the desired index type (e.g., ascending, descending).
Regular Maintenance: Periodically check and optimize indexes to ensure they remain effective as data grows and usage patterns change. Use tools like MongoDB's explain method to analyze query performance and index usage.
Streamlining the Mapping Process
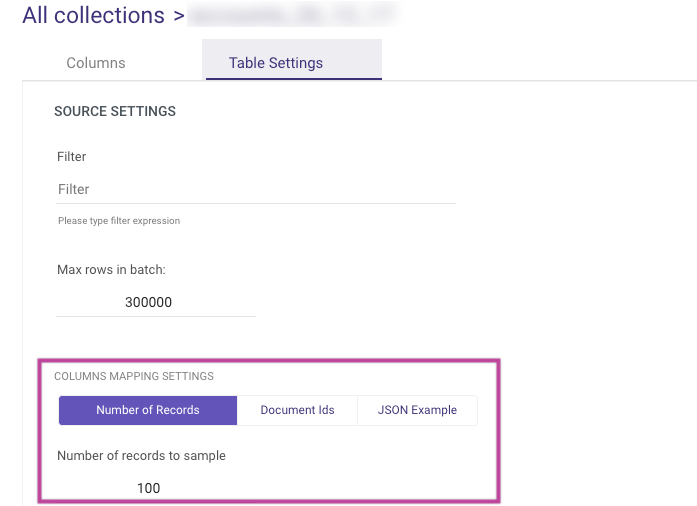
The Table Settings tab within the Schema section offers 3 powerful features to enhance the mapping process when working with a MongoDB collection. These features address the challenges of MongoDB's schemaless structure by offering greater flexibility and control over schema inference.
Number of Records
- By default, the mapping process samples the last 100 documents from the collection to infer the schema. Users can adjust this behavior by:
- Selecting a sample size of up to 10,000 records.
- Sampling either the first or last records based on their preference.
- This allows you to define the number and sequence of rows sampled, enabling a more tailored approach to schema detection.
Why is this important?
MongoDB collections lack table metadata due to their schemaless structure, making schema inference challenging. Sampling an insufficient number of documents may result in incomplete mappings.- By default, the mapping process samples the last 100 documents from the collection to infer the schema. Users can adjust this behavior by:
Document ID Mapping
- You can map data using specific Document IDs, ensuring that only relevant records are included in the schema mapping.
- Key behaviors:
- If no matches are found for the provided Document IDs, an error notification is displayed.
- If at least one match is found, the mapping process continues, and you will receive a notification about any unmatched IDs in the collection.
- This feature provides a more targeted mapping approach, reducing ambiguity and improving the relevance of the inferred schema.
JSON File Mapping
- Users can now upload a JSON file to define the mapping explicitly. This feature offers:
- Greater precision in specifying the structure of the collection.
- Enhanced control over the expected schema, minimizing errors caused by sampling variability.
- This method is ideal for advanced users who have pre-defined schema requirements or need to align with external data models.
- Users can now upload a JSON file to define the mapping explicitly. This feature offers:
Availability
The mapping features are accessible in both Legacy and Multi-Tables modes (excluding Change Streams) to ensure seamless integration across diverse data processing scenarios. You can find these options under the Table Settings tab in the Schema section.
Benefits
- Flexibility: The ability to adjust sample size, use specific Document IDs, or define mapping through a JSON file ensures adaptability to various use cases.
- Accuracy: These features minimize mapping errors, reducing the risk of incomplete or inconsistent schemas.
- Control: This empowers users with more options to tailor the mapping process to their specific needs.
Recommended Data Types for Incremental Keys in MongoDB to Ensure Accurate Filtering
When using incremental mechanisms in MongoDB, the behavior of comparisons depends on the data type of the field designated as the increment key. Below is a detailed explanation based on common data types:
1. Date/ISODate/Timestamp Fields
- Fields with the data type
Date,ISODate, orTimestampare compared chronologically. - The mechanism performs proper date-based comparisons, such as greater than (
>) or less than (<).
Example:
- A record with a timestamp of
2024-01-02is considered greater than a record with a timestamp of2024-01-01. - This ensures logical, time-sensitive ordering and filtering.
2. String Fields
- If the increment key field is a String, comparisons are based on alphabetical order, regardless of whether the string looks like a date.
- Strings that resemble dates (e.g.,
"12/31/2023"or"2024-01-01") are still treated as plain text during comparisons.
Example:
- The string
"12/31/2023"is considered greater than"1/1/2024"because string comparisons evaluate the characters alphabetically from left to right.
Key Considerations
- The data type, not the visual format of the field's values, determines the comparison logic.
- Date/ISODate/Timestamp fields enable chronological comparisons, whereas String fields use alphabetical ordering.
Recommendation
To ensure accurate incremental updates based on time or date values:
- Verify that the increment key field is of the correct data type (
Date,ISODate, orTimestamp). - Avoid using strings for date-like values unless intentional string-based ordering is required.
Was this article helpful?