MySQL CDC Overview
- 5 Minutes to read
- Print
- DarkLight
- PDF
MySQL CDC Overview
- 5 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
What is CDC Extraction?
Rivery's Log-Based extraction mode provides a real-time stream of any changes made to the databases and tables configured, eliminating the need to implement and maintain incremental fields or retrieve data via select queries. It also allows you to retrieve deleted rows and schema changes from the database.
How is CDC Extraction configured in MySQL?
The CDC mechanism for MySQL is based on its binary log (more commonly known as binlog). Like all databases, logging needs to be specifically enabled for MySQL ensure Change Data Capture is taking place. This feature comes pre-built for MySQL Server and just needs to be turned on.
Enabling this log is a straightforward operation in MySQL - the following three parameters just need to be set up correctly in your MySQL database server:
binlog_format
binlog_row_image
expire_logs_days
Configuring the expire_logs_days to the right number of days is crucial for succeeding in bringing data from the log constantly. The trade-off here is storage vs. retention of the data and recovering when the failures happen. This means setting up expire_log_days to a very long time will reduce the available storage in the MySQL server or cluster, and setting it to a short time may purge the log before Rivery will take the new data if something is wrong in the connector.
Therefore, the recommendation number in setting up the expire_logs_days parameter for Rivery is 7 (days). This recommendation is balanced between the storage needs of the binlog and the retention Rivery asks for in a case of failure in fetching the log.
CDC Point in Time Position Feature
The CDC “Point in Time” Position feature allows users to gain deeper insights into the operational details of a River's streaming process. This functionality is essential for data recovery and synchronization, enabling users to locate and retrieve data from a specific point in history using the exact information stored in the CDC log position. For additional information, refer to our documentation.

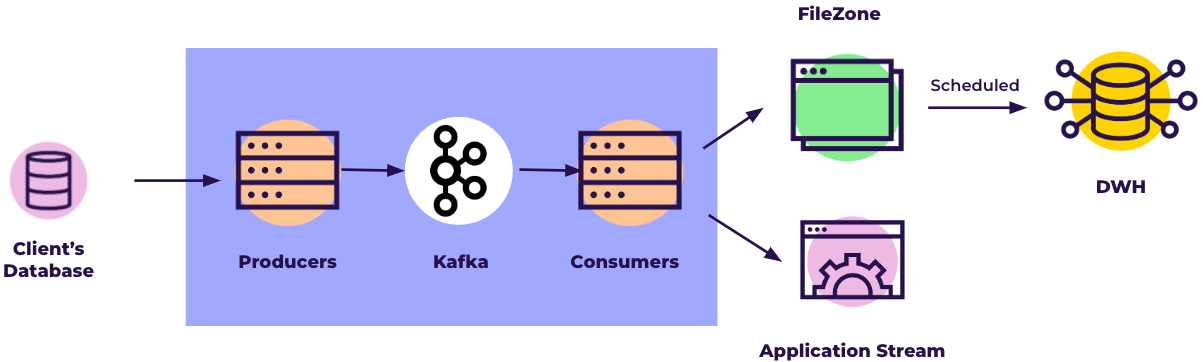
How does CDC Extraction work in Rivery?
In order to pull data using the Change Data Capture architecture, Rivery continuously pulls new rows in written in the binlog. Rivery cannot rely on the entire log history already existing prior to setting up a river in order to get the historical data from the database. This is because MySQL normally maintains and purges the binlog after some period of time (defined using expire_logs_days parameter).
In order to align the data and the metadata as it is the first run, Rivery makes a full snapshot (or migration) of the chosen table(s) using the Overwrite loading mode. After the migration ends successfully, Rivery takes the existing binlog records and makes an Upsert-merge to the target table(s), continuing to fetch new records from the log as they are created.
The MySQL connector in Rivery reads the binlog records and produces change events for row-level INSERT, UPDATE, and DELETE commands into the FileZone files. Each file represents a group of operations made in the database in a specific timeframe. The data from the log is streamed constantly (by timeframes of maximum 15 minutes) into the FileZone path determined in the river and pushed into the target by the river's scheduled frequency. This approach means the data is saved, first and foremost, in the FileZone, and then can be pushed anytime into the target DWH.
For more information regarding the FileZone configuration in Rivery, you can refer to the target configuration documentation.
A 'Sequence' CDC Deployment
Discrepancies in transaction records can arise when two users simultaneously execute identical transactions, causing conflicts in the timestamp field. Recognizing this challenge, Rivery has implemented a "sequence" Change Data Capture (CDC) mechanism to tackle this issue.
Rivery has enhanced each emitted record from the database by incorporating two extra metadata fields: '__transaction_id' and '__transaction_order'.
The '__transaction_id' field serves as a unique identifier for each transaction, ensuring that no two transactions share the same identifier. This uniqueness allows for precise identification and differentiation between transactions, mitigating conflicts arising from identical timestamps.
Furthermore, the '__transaction_order' field denotes the order in which the transactions were emitted from the database. By incorporating this field, the sequencing of transactions can be accurately maintained, enabling downstream systems such as Apache Kafka or AWS Kinesis to process and order transactions correctly.
The inclusion of these metadata fields guarantees that the ordering of transactions is preserved throughout the River. As a result, smooth and accurate transaction flows can be achieved, resolving the discrepancies that previously arose from transactions with identical timestamps.
The additional fields are depicted in this table:
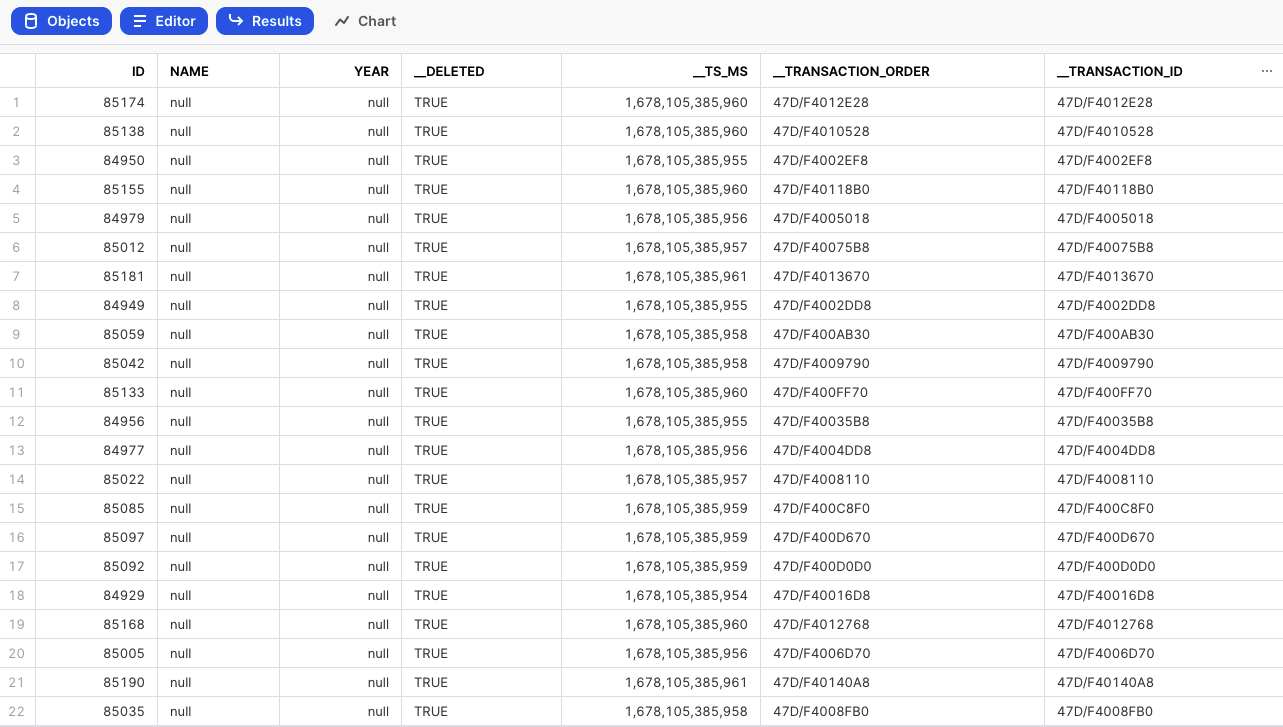
For further details about Change Data Capture (CDC) Metadata Fields, please refer to our Database Overview document.
Architecture Diagram
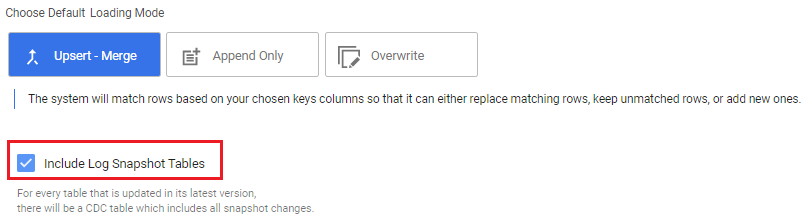
Load tables with Log-Snapshot tables
Loading your data from a database to a target using CDC has an additional capability which is pulling of the log snapshot table.
Using the following use case table:
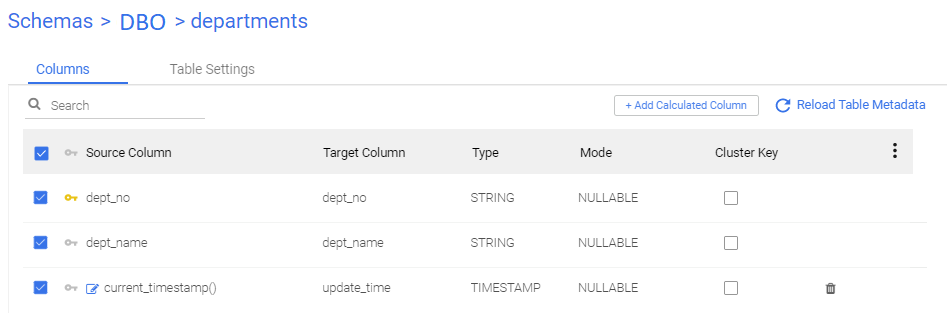
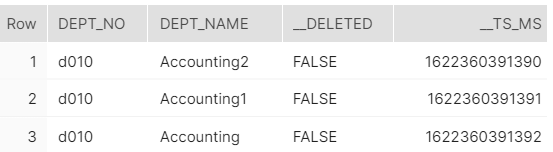
To attach each log snapshot table to its respective table, we use the same naming convention with the suffix "_log". E.g., DEPARTMENTS will be the table itself being passed to the target using CDC, and DEPARTMENTS _LOG will be its respective log snapshot.

Each action performed on the log snapshot table is added to the table, along with information about when it was changed (recorded under the column __ts_ms) and if it was deleted (recorded under the column __deleted).
Please Note:
The __DELETED column is introduced only when a delete action occurs.
It is essential to note that _log tables are designed to be append-only, and in the event of a connection issue, we pull data from the last successful pull to prevent any data loss.
As a result, _log tables may contain duplicate records.
The original table:

In DBO.DEPARTMENTS table, there are 2 colums: DEPT_NO and DEPT_NAME. Additionally, there is a calculated expression in the target's mapping which uses current_timestamp().
Before enabling CDC (Change Data Capture) and migrating the Rivers, the automatically included fields __deleted and __ts_ms have null values for all records.
The log snapshot table is loaded only when the Status is set to "Streaming," as explained further below:
These are the possible configurations when using CDC:
Each river will start with status = Waiting For Migration, where we will take everything present in the table.

Scheduling
After the first run, the status will be changed to Streaming where we will also load the log snapshot table. The scheduling of the rivers tells us what is the frequency to write the logs to the filezone, this option can be changed later on in the river's "Settings and Schedule".
Was this article helpful?