Partitioning and clustering in BigQuery
- 4 Minutes to read
- Print
- DarkLight
- PDF
Partitioning and clustering in BigQuery
- 4 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Overview
A partitioned table is a table divided to sections by partitions. Dividing a large table into smaller partitions allows for improved performance and reduced costs by controlling the amount of data retrieved from a query.
Clustering sorts the data based on one or more columns in the table. The order of the clustered columns determines the sort order of the data. Clustering can improve the performance of certain types of queries, such as queries that use filter clauses and queries that aggregate data.
You can select up to 4 fields to cluster from and only a single field to partition upon. When you partition on a field, you can select the partition granularity which includes "YEAR", "MONTH" and "DAY" for columns of date type and the additional "HOUR" for timestamp. The granularity determines the boundaries of the partitions, for example if you choose day granularity each day will be a separate partition in BigQuery.
When you cluster a table using multiple columns, the order of columns you specify is important. The order of the specified columns determines the sort order of the data.
For source to target rivers selecting the SQL dialect and the partition settings is done in the target step under advanced options.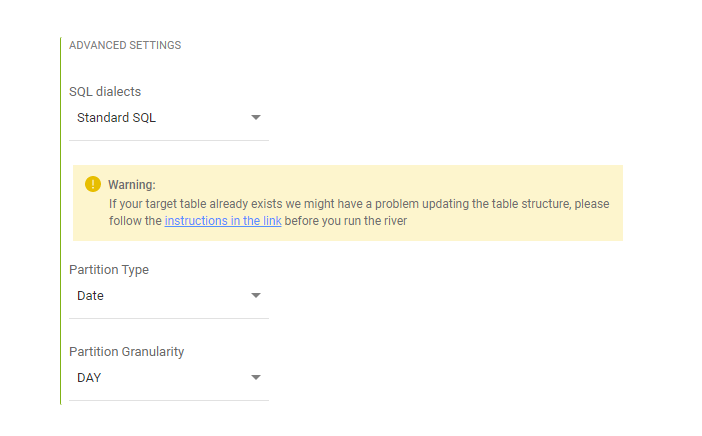
In the mapping section you will be able to point to the partitioned and clustered fields and their order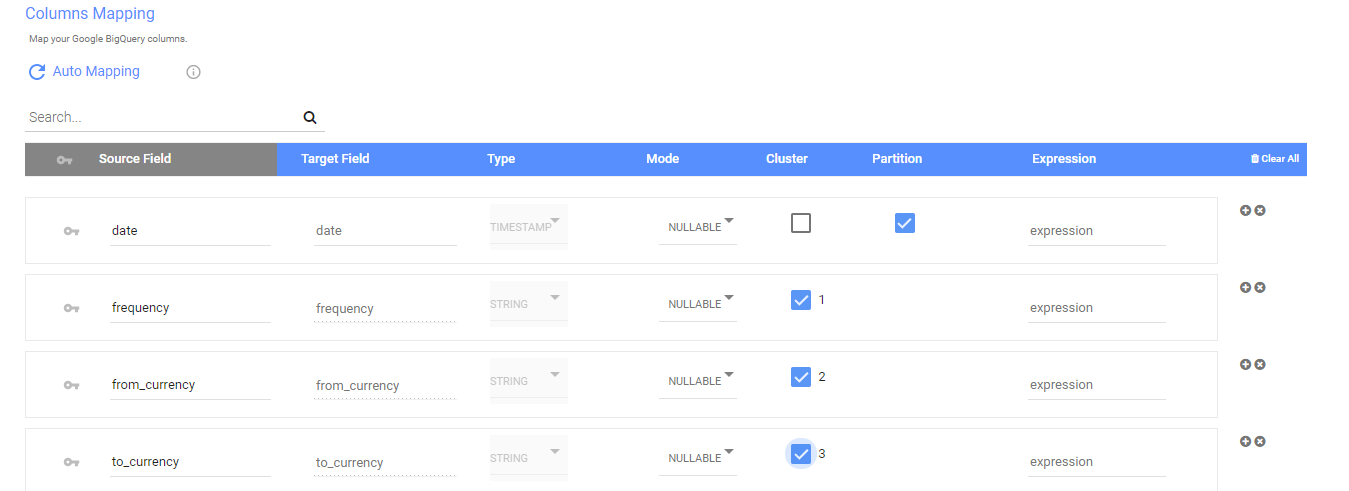
Multi-table rivers have a general setting for the SQL dialect in the target section, and each table has its own setting similar to Data Source to Target rivers where you can decide the dialect for that table and if to set a partition field. In each table mapping you can select the cluster and partition accordingly.
Switching between Legacy SQL and Standard SQL in Rivery
There are differences between Legacy SQL and Standard SQL which must be taken into account when switching between dialects. For instance, not all functions and functionalities are supported, and there are syntax differences.
For example in Standard SQL we query tables like this:
`bigquery-public-data.samples.shakespeare`
While in Legacy SQL it is done in this manner:
[bigquery-public-data:samples.shakespeare]
Find out more about the differences between Legacy SQL and StandardSQL in BIgQuery documentation.
Please make sure your river is aligned when you make the switch.
With Standard SQL, we flatten columns of RECORD type, but for Legacy SQL we do not. While switching from Legacy SQL to Standard SQL, if you have columns of RECORD type, expect the final table in Standard SQL mode to have multiple new flattened columns instead of a single one .
If your target table already exists, we highly recommended NOT to switch back to Legacy SQL mode.
Append or merge functions may not be properly supported which could cause data loss. This is due to the differences in how records are handled between the two SQL dialects as mentioned above.
In addition, If the table has clusters or partitions the river will fail as it is not possible to query clustered or partitioned tables with LegacySQL syntax.
Logic river handles records with StandardSQL in the following manner:
- If the logic step is not mapped and the flatten results checkbox is not checked - the records will be loaded as-is.
- If the logic step is not mapped and the flatten results checkbox is checked - you will be prompted to map the step.
- if the logic step is mapped and the flatten results checkbox is checked - the records will be flattened.
- if the logic step is mapped and the flatten results checkbox is not checked - You will be prompted to either remove the mapping, remove the column from the mapping or uncheck the flatten results checkbox
| Logic step status\flatten results checkbox status | flatten results checkbox is not checked | flatten results checkbox is checked |
| Logic step not mapped | you will be prompted to map the step | the records will be loaded as-is |
| Logic step mapped | You will be prompted to either remove the mapping, remove the column from the mapping or uncheck the flatten results checkbox | the records will be flattened |
Creating or altering partitions and/or clusters on an existing table
The process of creating or altering partitions on an existing table requires the table be dropped and recreated with the desired settings.
Follow the steps below:
- Create a new temporary table with the existing data of the target table, this is when the clustering and partitioning is specifiedPL/SQL
CREATE TABLE < dataset_name > . < tmp_table_name > PARTITION BY TIMESTAMP_TRUNC( < timestamp_column > , { DAY | HOUR | MONTH | YEAR }) CLUSTER BY < column1 > , < column2 > AS SELECT * FROM < dataset_name > . < table_name > Specific example: CREATE TABLE `dwh.temp_users` PARTITION BY TIMESTAMP_TRUNC(inserted_at, DAY) CLUSTER BY user_id AS SELECT * FROM `dwh.users`PL/SQL - Now that the data is safely stored in the new temporary table you can drop the target table. Do note that until the process is completed you will not have access to the data in the target table.PL/SQL
DROP TABLE < dataset_name >.< table_name > Specific example: DROP TABLE dwh.users - Use the BigQuery console UI to copy the temporary table to the target table. This will duplicate the temp table and rename it. Afterwords the temp table will be dropped.
- Select the table you want to copy from the Resources pane.
- Below the Query editor, click Copy table
- In the Copy table dialog, under Destination:
For Dataset name, choose the < dataset_name > or in our case "dwh"
For Table name, choose the < table_name > or in our case "users".
Click on copy table.
- Drop the temporary table.PL/SQL
DROP TABLE < dataset_name >.< tmp_table_name > Specific example: DROP TABLE dwh.temp_users
Was this article helpful?