Amazon RDS/Aurora PostgreSQL CDC Setup Guide
- 2 Minutes to read
- Print
- DarkLight
- PDF
Amazon RDS/Aurora PostgreSQL CDC Setup Guide
- 2 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Introduction
Amazon Relational Database Service (RDS) and Amazon Aurora, both fully managed by Amazon Web Services (AWS), offer scalable and reliable infrastructures for running PostgreSQL databases in the cloud. This document will guide you through configuring PostgreSQL on Amazon RDS or Aurora, including setting up Change Data Capture (CDC) to efficiently track and capture database changes.
Prerequisites
- Ensure you are running PostgreSQL 10 or higher.
- Server and Database permissions are required to change server configuration (depending on the PostgreSQL cloud/on-prem provider).
Notes on PostgreSQL Server Architecture
- Logical Decoding does not support DDL changes. Consequently, Rivery cannot report DDL change events to the database.
- Only primary servers in the cluster can utilize logical decoding replication slots. This feature is not available for warm or hot standby replicas. If the primary server fails or becomes detached, log fetching will stop, causing the River to fail.
- Only UTF-8 character encoding databases are supported.
PostgreSQL setup for Amazon RDS / Aurora
Prerequisite:
Ensure logical decoding is enabled for a PostgreSQL RDS instance by following the the PostgreSQL documentation.
AWS RDS PostgreSQL v10+ comes pre-configured with a replication role, allowing CDC to be enabled.
To get started, go to the AWS RDS console.
Click Services in the upper left corner, then select RDS.

Under Parameter Groups, select Create Parameter Group.
Select the parameter group family corresponding to your PostgreSQL server version.
For an Aurora cluster, choose DB cluster parameter group as the parameter group type. For RDS, choose DB parameter group.
Name the group (e.g., Postgresql-rivery-cdc) and click Create.
Enter the newly created parameter group to change and enable configurations associated with the current server.
Modify the following parameters:
rds.logical_replication = 1
rds.log_retention_period = 10080 # 7 days
wal_sender_timeout = 30000

Click Save Changes.
Navigate to the Databases section and select the CDC Postgres server you want, then click Modify.
In the DB parameter group section, select the parameter group created in step 3.
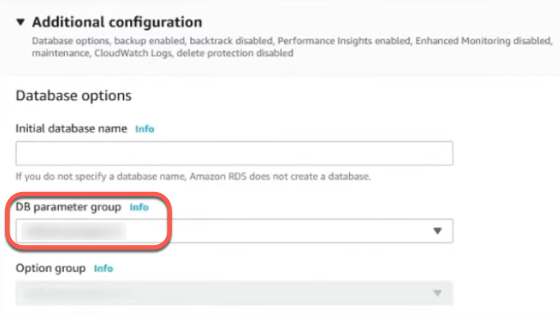
Click Continue, then Apply Immediately under Modification Scheduling.
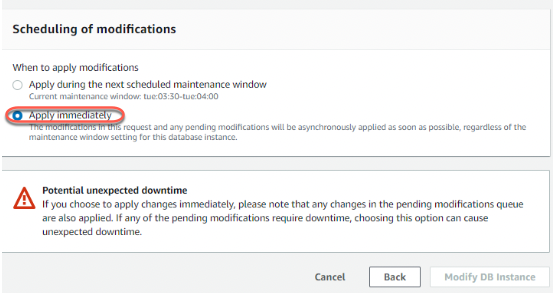
Restart may required
A restart may be required to apply the new parameter values. You may need to reboot the writer DB instance.
- Validate - Execute the following query as the DB master user to ensure that the wal level parameter is set to logical:
SHOW wal_level
Configuring an Additional Replication Role in Amazon RDS
The default user created with an instance already possesses a replication role, allowing CDC to be enabled. To add an additional user run the following commands:
CREATE USER rivery_user WITH PASSWORD 'your_password';
GRANT rds_replication TO rivery_user;
Please Note:
If you manually manage your replication slots and publications, please refer to the "Configuring PostgreSQL CDC Replication Slots and Publications" document.
Connect to Rivery
Follow the PostgreSQL Connection documentation to connect to the Rivery console.
Was this article helpful?