Python DataFrames
- 8 Minutes to read
- Print
- DarkLight
- PDF
Python DataFrames
- 8 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Python is currently only available on Professional and Enterprise plans by default. If you have a Trial or Starter plan and would want to use it, please contact us and we will activate it for you.
Overview
A DataFrame is a data structure that organizes data into a two-dimensional table of rows and columns. DataFrames are advanced data structures used in current data analytics because they provide a dynamic and intuitive means of storing and interacting with data.
Rivery's DataFrames solution offers a user-friendly method of manipulating data that takes advantage of the enormous potential of machine learning and other data techniques implemented in Python.
Use Cases
DataFrames can be used in a variety of cases:
- Use a Custom Landing Zone
- Use DataFrames as a Source.
- Use DataFrames as a Target.
- Manipulate the DataFrame using Python.
- Use pandas to replace an existing DataFrame.
- Use a DataFrame that has already been configured from another river.
Working With DataFrames
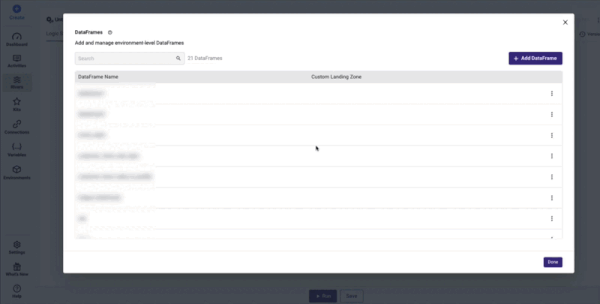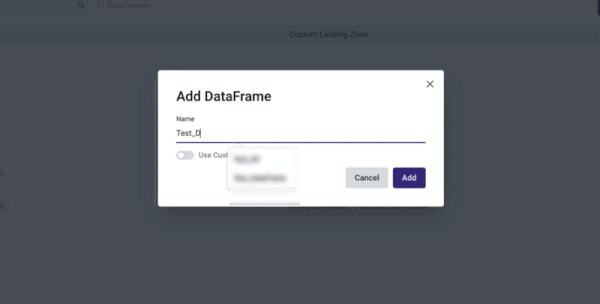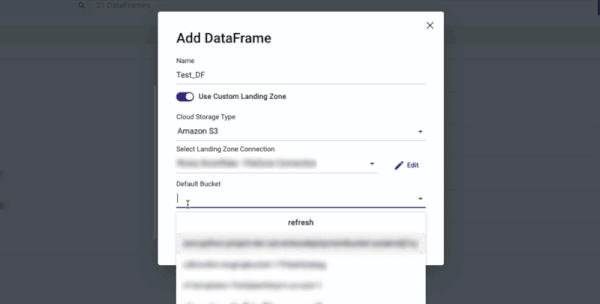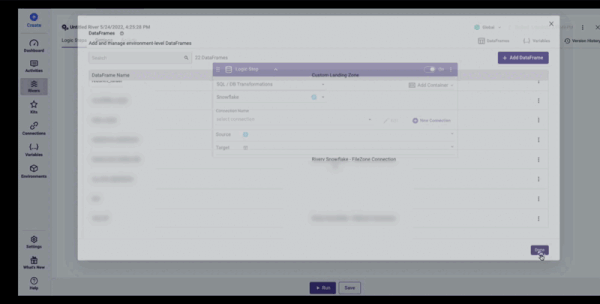
Configure DataFrames
Following the creation of a Logic River simply select 'DataFrames' from the menu in the top right corner and complete the on-screen instructions:
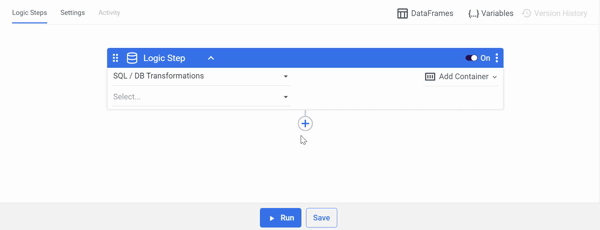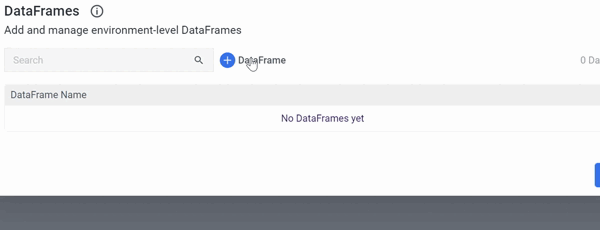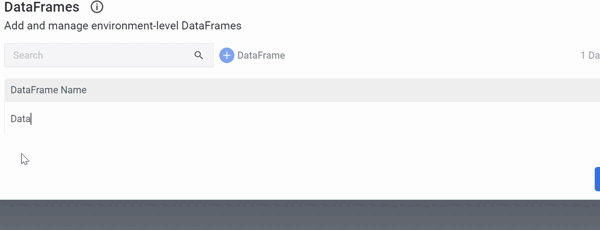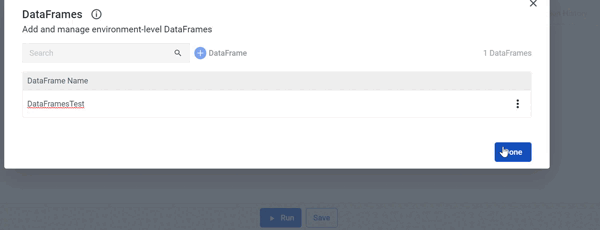
Note:
The '+DataFrame' button was renamed '+Add DataFrame' and relocated to the window's right corner.
Custom Landing Zone
Rivery allows you to use a custom FileZone, which we call Landing Zone, to manage your data in your own S3 bucket. A bucket is a container that holds objects. An object is a file and any metadata that describes that file.
Note: If you don't use a Custom Landing Zone, a Rivery Bucket will be used by default and it will store the DataFrame until deleted using the "delete()" Python function.
Prerequistes
- You must first connect to Amazon S3 before using a Custom Landing Zone.
- If you're new to Amazon S3 buckets, start with the S3 documentation.
Using a Custom Landing Zone
Use a Custom Landing Zone by following the on-screen instructions:
Bucket Stored Objects
Your stored objects will be saved in a Parquet file. Parquet is an open source file format designed for flat columnar data storage. Parquet works well with large amounts of complex data.
Locate your parquet file by following the navigation path:
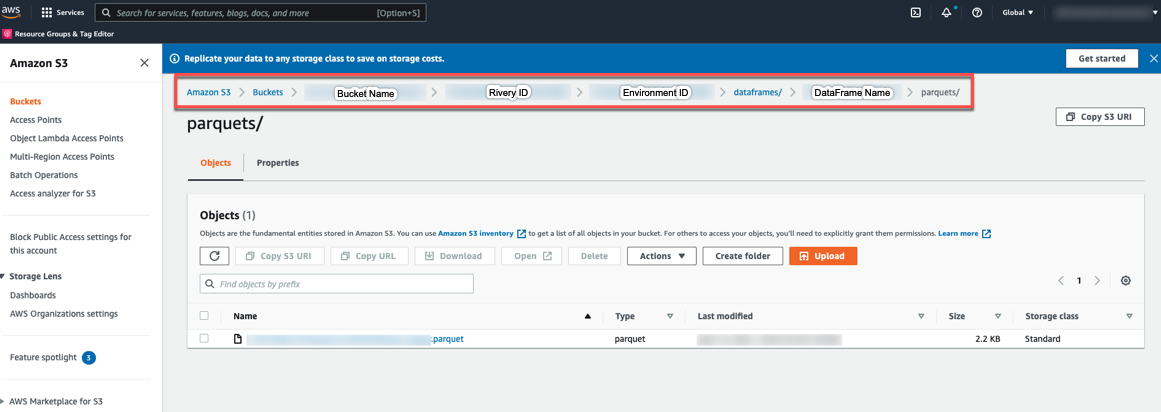
Note: Make sure to include the proper policy so that your cloud storage can use dataframes successfully.
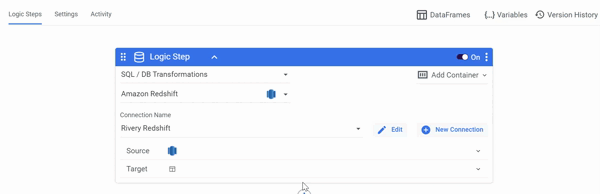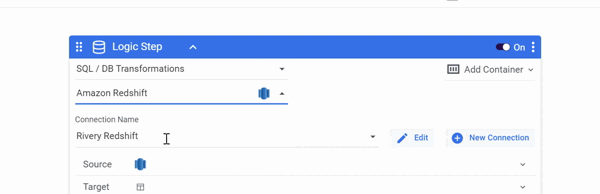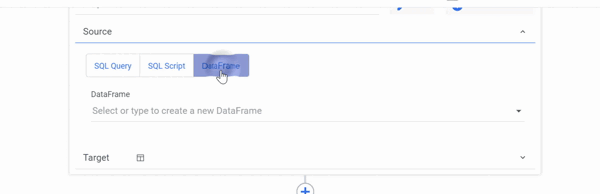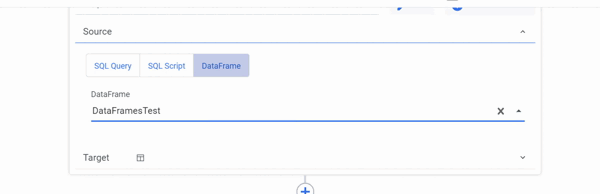
DataFrames as a Source
Select the SQL / DB Transformations Step type and your Connection first, then you can create new DataFrames or use pre-configured DataFrames from other rivers as a Source in Logic River.
Note:
Only a Table can be selected as a Target when using DataFrames as a Source.
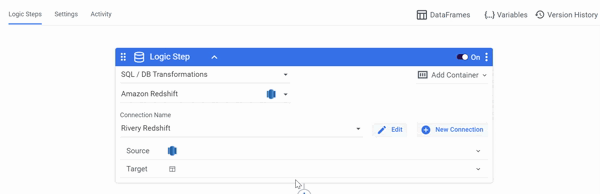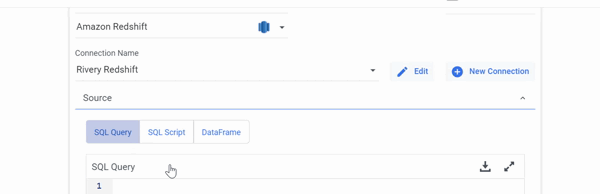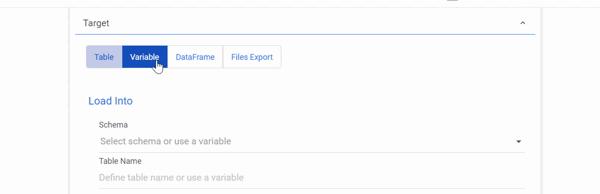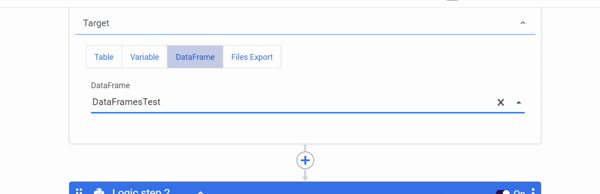
DataFrames as a Target
Select the SQL / DB Transformations Step type and your Connection first, then select SQL Query as a Source, after which you may either create new DataFrames or use pre-configured DataFrames from other rivers as a Target in Logic River.
Note:
- Only a SQL Query can be selected as a Source when using DataFrames as a Target.
- The Dataframe used in the Target is overwritten with the new data pulled using the SQL query every time you click Run a river.
Manipulate The DataFrame Using Python
You can manipulate your Dataframe by using the code samples below or by implementing various pandas functions.
To input a Python script, follow the on-screen guidance:
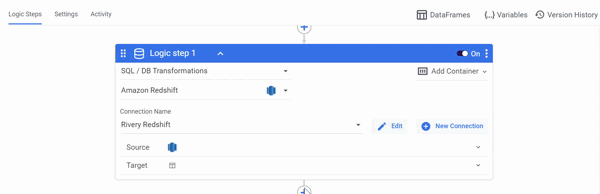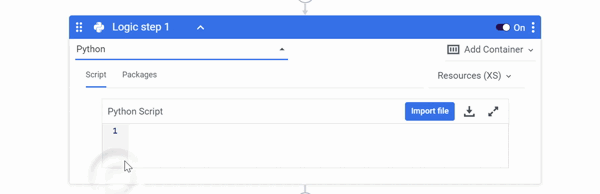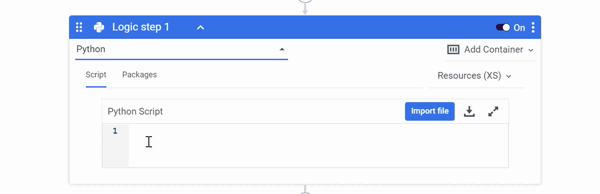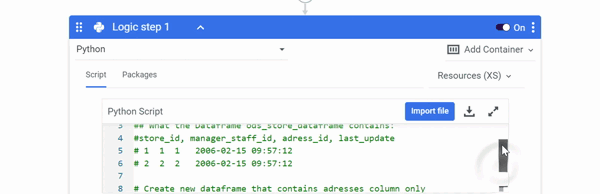
DataFrames Menu
Any new or pre-configured DataFrames can be edited, downloaded to your local computer, cleared of values, and deleted.
To view the menu, click the three dots on the right side of the row your DataFrame is on:
DataFrames and Environments
Dataframes are associated with the Environment rather than a specific River, meaning that any updates or deletions of a DataFrame in a particular River will also be reflected in the Environment that the River is part of.
Deploying DataFrames in Different Environments
Rivery makes it possible to migrate preconfigured DataFrames between Environments.
Go to the Environment View, pick the Deployment tab, and then follow the on-screen instructions in the Deployment section of our Environments guide.
Please Note:
- Ensure that the names of the DataFrames in the Source Environment and the Target Environment are distinct.
- Encrypted variables won't be copied from one Environment to another when deploying DataFrames between Environments.
- Two settings were added specifically for DataFrames to the Deployment procedure's Settings tab.
Example of a Common Use Case
A common use case for using Python with DataFrame in Rivery is pulling data from a database and inserting it in a target DataFrame using a SQL query. The DataFrame is then manipulated in Python before being pushed to the database.
The following use case will be performed in 3 Logic Steps as shown below:
Using a SQL query, pull data from your database into a DataFrame:
- Select 'SQL / DB Transformations' as the Logic Step type.
- In the Database Type, choose your database.
- Select Connection Name.
- Enter your SQL query in the Source field.
- In the Target field, choose 'DataFrame' and specify your DataFrame.
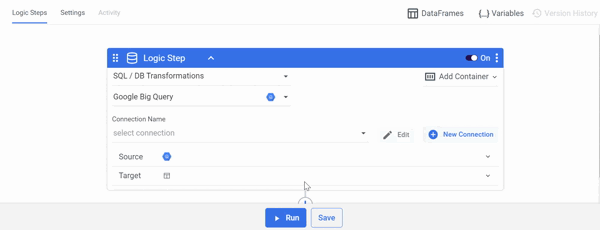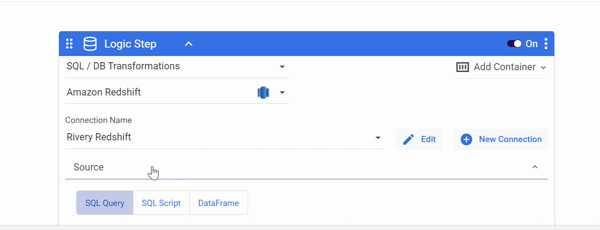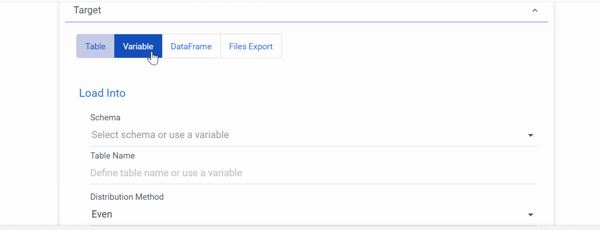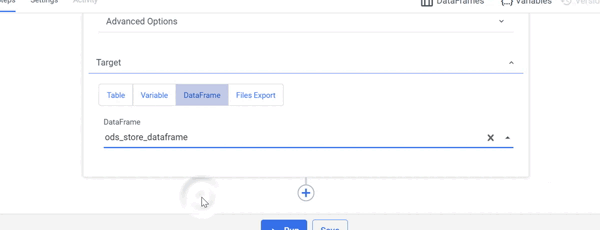
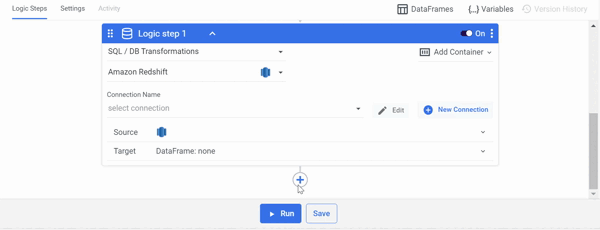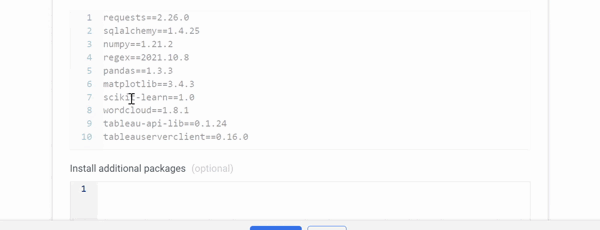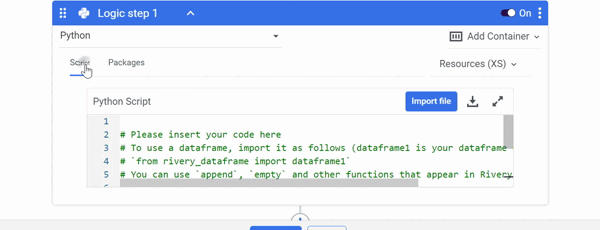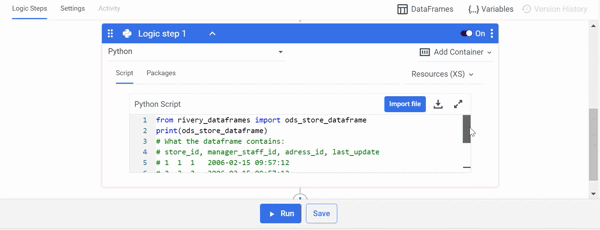
Manipulate the DataFrame using Python:
- Select 'Python' as the Logic Step type.
- Check to see if the necessary Python packages are installed.
- Choose a resource based on the amount of data you intend to consume.
- To manipulate the DataFrame, Import your Python script in the 'Script' field.
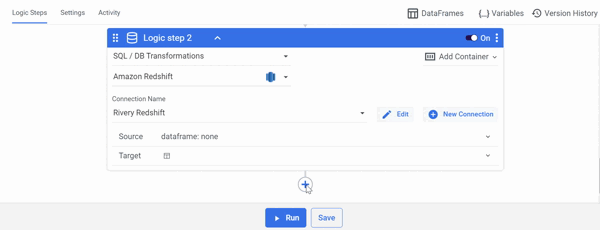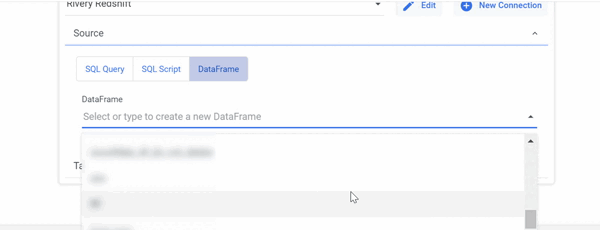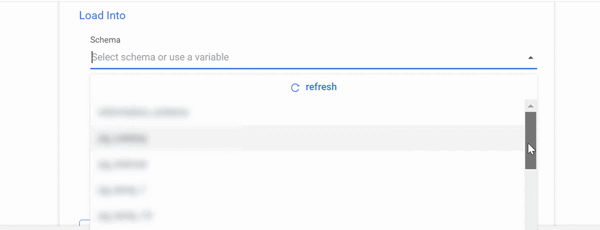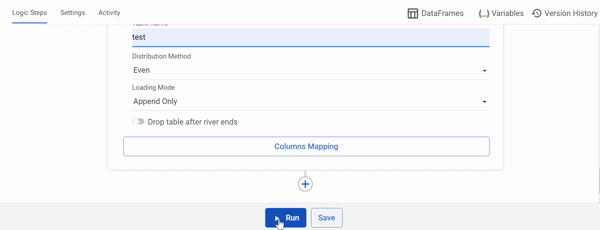
Push the DataFrame's data to your database:
- Select the required DataFrame in the Source field.
- In the Target field, choose Table and enter the load information.
- Click Run.
Video Illustration
Here's a straightforward visual demonstration that shows how to manipulate Python Dataframes:
Code Samples
Please Note:
Once a DataFrame is imported, it serves as a Pandas object, providing access to all the functions offered by the Pandas library.
Here are a few code samples of what DataFrames can do:
Basic Import
from rivery_dataframes import DATAFRAME_NAME
print(DATAFRAME_NAME)
Save
from rivery_dataframes import EXISTING_DATAFRAME
EXISTING_DATAFRAME.save(Your Input)
Using Pandas, Create a New Dataframe
import pandas as pd
from rivery_dataframes import TempDF
new_dataframe = pd.DataFrame()
TempDF.save(new_dataframe)
More information is available in the pandas Dataframe documentation.
Empty
from rivery_dataframes import EXISTING_DATAFRAME
EXISTING_DATAFRAME.empty()
Using Chunks
This is an import solution for large amounts of data.
from rivery_dataframes import DATAFRAME_NAME
DATAFRAME_NAME.chuncked = NUMBER_OF_CHUNCKS
for df in DATAFRAME_NAME:
print(df)
Extract and Save .csv File
from rivery_dataframes import NEW_DATAFRAME
print(f"Download csv from {CSV_URL}")
csv = requests.get(CSV_URL)
print("Convert csv to dataframe")
new_dataframe = pd.read_csv(csv)
NEW_DATAFRAME.save(new_dataframe)
Fetch a Specific Column From a Dataframe
from rivery_dataframes import EXISTING_DATAFRAME
# Given the DataFrame structure:
# max_speed shield
# cobra 1 2
# viper 4 5
# sidewinder 7 8
# To fetch the 'max_speed' column in its entirety, use this command:
EXISTING_DATAFRAME.loc[:, 'max_speed']
DataFrame Usage Notes
In the Rivery Python implementation, DataFrame usage with [ ] is not supported.
Incorrect Usage:
A_DATAFRAME['key']Correct Usage:
DataFrame should only be used with functions, for example:A_DATAFRAME.function()If you encounter any script-related errors, please follow these steps:
- Print the DataFrame types using:
print(A_DATAFRAME.types)- Refer to the documentation of the chosen Source (e.g., Amazon Redshift Supported Data Types).
- If any type is not supported, convert it using:
A_DATAFRAME.astype({'col1': 'int32'}).
Required Permissions
Custom File Zone
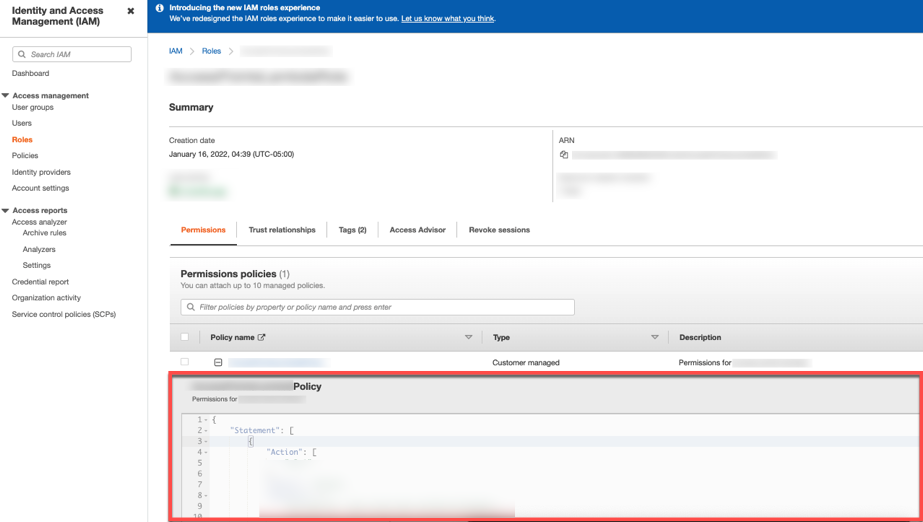
For DataFrames to work properly with your cloud storage, be sure to include the following policy in the AWS IAM console:
- If you're using Snowflake, copy this permission policy:
{
"Sid":"RiveryManageFZObjects",
"Effect":"Allow",
"Action":[
"s3:DeleteObject",
"s3:ListObjectsV2",
"s3:ReplicateObject",
"s3:PutObject",
"s3:GetObjectAcl",
"s3:GetObject",
"s3:GetBucketLocation",
"s3:ListMultipartUploadParts"],
"Resource":"arn:aws:s3:::<RiveryFileZoneBucket>/*"
}
- If you're using Redshift, copy this permission policy:
{
"Sid":"RiveryManageFZObjects",
"Effect":"Allow",
"Action":[
"s3:ListObjectsV2",
"s3:ReplicateObject",
"s3:PutObject",
"s3:GetObjectAcl",
"s3:GetObject",
"s3:DeleteObject",
"s3:PutObjectVersionAcl",
"s3:PutObjectAcl",
"s3:ListMultipartUploadParts"],
"Resource":"arn:aws:s3:::<RiveryFileZoneBucket>/*"
}
Once you've copied the relevant policy for you, go to the AWS IAM console.
Click 'Roles' from the menu and then select the role you created for Rivery. Next, scroll down to the Permission section and paste the policy.
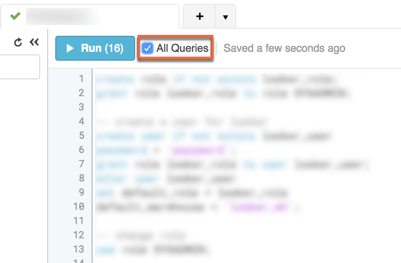
Using Snowflake as a Target
To ensure that the information from DataFrames transfers successfully to Snowflake when using Snowflake as a Target, take the following steps:
- Copy the following query:
GRANT USAGE ON SCHEMA public TO <Rivery_User>; GRANT SELECT ON ALL TABLES IN SCHEMA public TO <Rivery_User>; - Enter the Snowflake console.
- Check the box next to All Queries.
- Paste the query to the console's main page.
Please Note:
Users can choose the database and schema for Rivery to use in managing the generated DataFrame. In case no selection is made, Rivery will default to using the first database on the list and the 'PUBLIC' schema.
Please ensure that the permissions mentioned earlier are configured for the chosen schema/database.
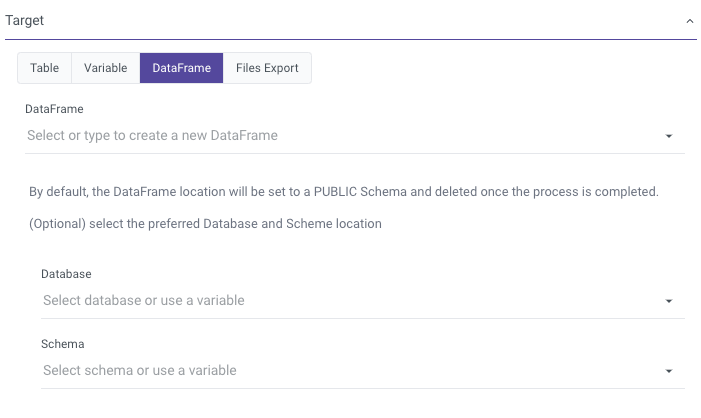
Limitations
When naming a DataFrame, avoid using the following characters:
Character Space " " Slash " / " and " \ " Period " . " Any type of brackets "(" and "[" and "{" Hyphen " - "
Note: The DataFrame will not be saved, and the River will fail to run.
- When designating column names within a DataFrame, only the following characters are compatible: ^([A-Z][a-z])([A-Z][a-z][0-9]_)*
Utilize Regex101 for testing and troubleshooting expression patterns. - Snowflake does not allow header columns containing the character "." in them.
If your script includes "." in the header columns, use the following command to fix the issue:NEW_DF = DATAFRAME_NAME.rename(lambda x: x.replace('.', '_'), axis='columns') DATAFRAME_NAME.save(NEW_DF) - If you're using Redshift, you'll need to create a Custom Landing Zone, and make sure it's in the same region as your Redshift cluster.
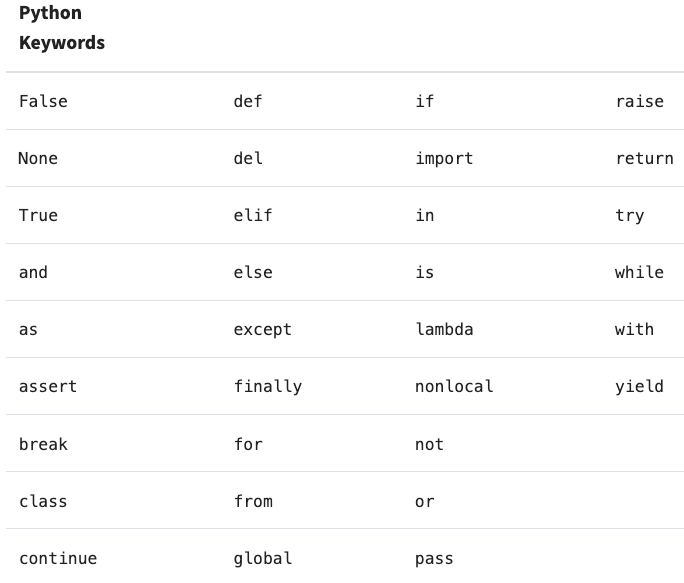
- Python reserved words cannot be used in Rivery as it may cause syntax errors and conflicts during River runs.
Here is a comprehensive list of all the reserved words in Python:
Temporary Limitations
- Kits/Environments do not support DataFrames.
- DataFrames are only supported for Amazon Redshift and Snowflake connections.
- DataFrames on Redshift connections are only supported for the following locations:
1. For Rivery US console - Redshift cluster located at us-east-1
2. For Rivery EU console - Redshift cluster located at eu-west-1
Was this article helpful?