Amazon Redshift Walkthrough
- 3 Minutes to read
- Print
- DarkLight
- PDF
Amazon Redshift Walkthrough
- 3 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
This guide will walk you through the steps needed to integrate data from a Redshift database into a cloud target using Rivery.
Connect To Redshift in the Rivery Console
To connect to your Redshift Database, consult the Redshift Connection documentation.
Pull Redshift Data Into a Target
Using Rivery, you can pull data from your Redshift tables and send that data into your target database.
First select 'Create New River' from the top right of the Rivery screen.
Choose 'Data Source to Target' as your river type.
In the 'General Info' tab, name your river and give it a description. Next, navigate to the 'Source' tab.
Find Redshift in the list of data sources and select it:

Define a Source Connection (this will be the connection created earlier in the process). If you do not yet have a Redshift connection in your Rivery account, you can create a new connection here by clicking 'Create New Connection.'

Next, choose your River mode.

- Multi-Tables : Load multiple tables simultaneously from Redshift to your target.
- Custom Query : Create a custom query and load it into your target.
- Legacy River: Choose a single source table to load into a single target.
Database Migration
For a detailed walkthrough of Multi-Tables mode, please refer to the Rivery Database Migration docs.
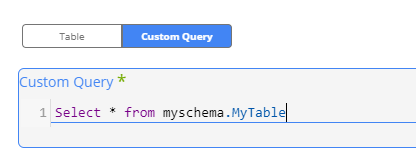
Pulling Data Using a Custom Query
You may also use the Custom Query in order to define a query data pull from Rivery. You may use any query that works in the source, using a specific SELECT query without any other statements. Rivery isn’t compatible using multi-statements or SQL Script in the custom query field.
Extract Method
Using Rivery, you can pull your data incrementally or pull the entirety of the data that exists in the table:
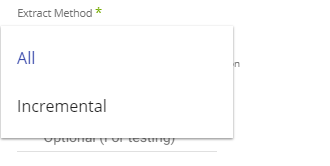
All: Fetch all data in the table using Chunks.
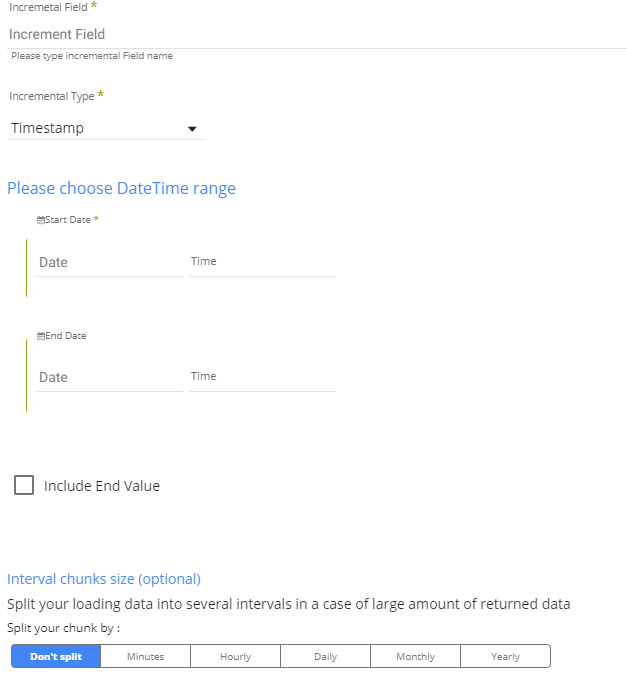
Incremental: Gives you the option to run over a column in a table or your custom query top SELECT. You can run over it by filtering Start and End dates or Epoch times
Moreover, you may choose to run over the date using Daily, Monthly, Weekly, or Yearly chunks.
Please define the incremental Field to be used in the Incremental Field section. After choosing the incremental field, choose the Incremental Type and the dates/values you would like to fetch.
Note: Rivery will manage the increments over the runs using the Maximum value in the data. This means you will always get the entire data since the last run, which prevents data holes. You just need to configure your river once.
Recommended : Define your incremental field in Rivery over a field with an Index or Partitions key in the table.
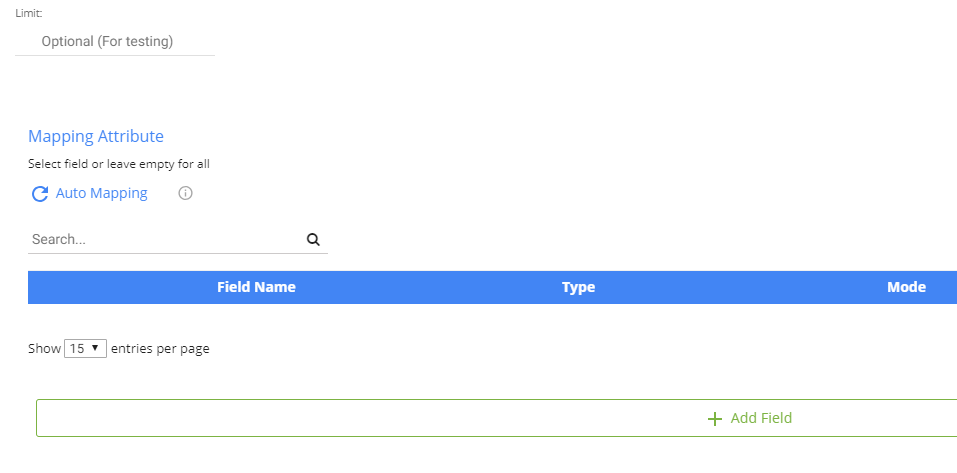
Limit and Auto Mapping
After defining the extract method, you may choose a limit of top N rows to fetch. Rivery will set your Schema using the Auto Mapping feature. You can also choose fields you want to fetch in the Mapping table and add fields on your own.
Legacy River Mode
This river mode allows for a load of a single source table into a single target table.
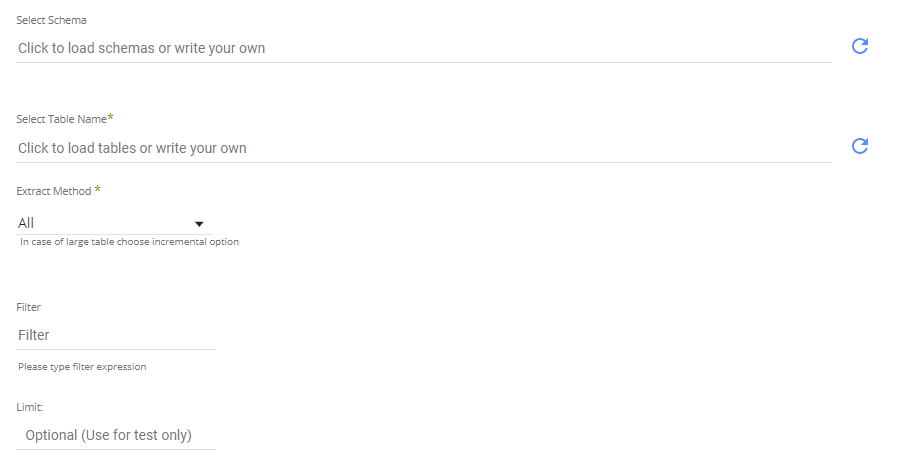
In the above screenshot, there are steps to define the source table to pull (Rivery will auto-detect available schemas and tables), the extraction method to use, and options for filters or row limits on the data pull.
Multi-Table Mode
Load multiple tables simultaneously from SQL Server to your target. There are two Default Extraction Modes: Standard Extraction and Log-Based.
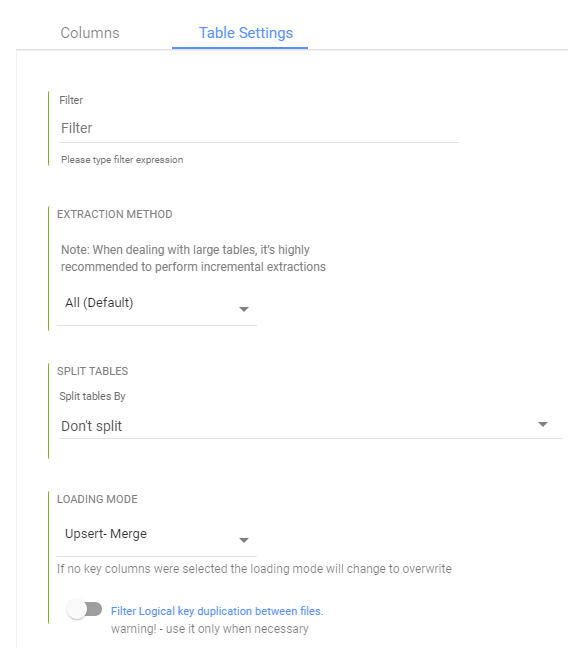
On the 'Table Settings' tab you are able to edit the following:
- Change the loading mode
- Change the extraction method. If 'Incremental' is selected, you can then define which field will be used to define the increment.
- Filter by expression that will be used as a WHERE clause to fetch the selected data from the table.
Schedule The River
Once the creation of the river is complete, navigate to the 'Schedule' tab and click 'Schedule Me.'

Choose the frequency at which to schedule the river.
To notify certain users about a river failure or warning, enable notifications below:
You can edit your {Mail_Alert_Group} in the Variables page (find this in the left-hand pane of the browser).
Monitor The River
During the river run, or after the run has complete, you can monitor the river in its 'Activities' tab.
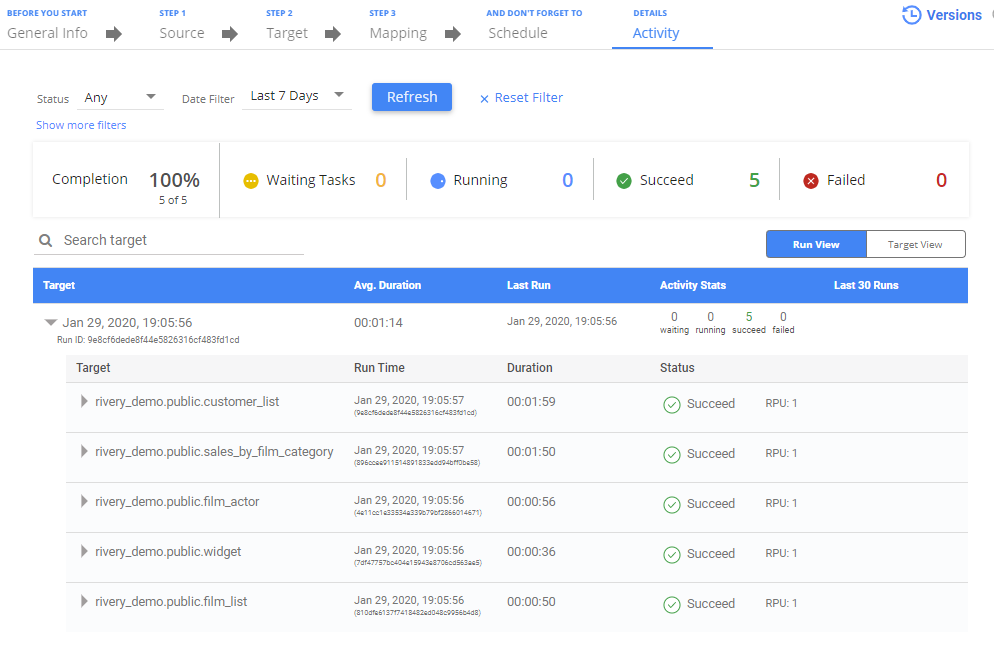
In this tab, you can monitor each of the status of the current river run. For the Multi-Table mode, you can monitor at the table-level (see above).
By toggling between 'Run View' and 'Target View' you can see the river results grouped either by time of run or by target location.
Check out the Targets section to find out how to load the data to your target data warehouse.
Was this article helpful?