Creating a Connection to Databricks
- 3 Minutes to read
- Print
- DarkLight
- PDF
Creating a Connection to Databricks
- 3 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Introduction
Databricks provides a managed service for data processing and transformation on a datalake. It uses Delta Lake, an open source solution developed by Databricks, which enables the creation, management, and processing of data using the Lakehouse architecture.
This guide will show you how to set up the required credentials and configurations for using Databricks with Rivery.
Recommendation
When establishing a connection, you have the option to use the Databricks Partner Connect guide. By following this guide, a fully functional Databricks connection will be automatically generated in Rivery.
Prerequisites
A valid Databricks Admin Account and Workspace.
Create a SQL Warehouse
To employ Databricks as a target, it is essential to perform operations on the existing SQL Warehouse. To create a new SQL Warehouse, please follow the steps outlined below:
Login into your Databricks workspace.
Go to SQL console.

Click on SQL Warehouse and then Create SQL Warehouse at the top right corner.
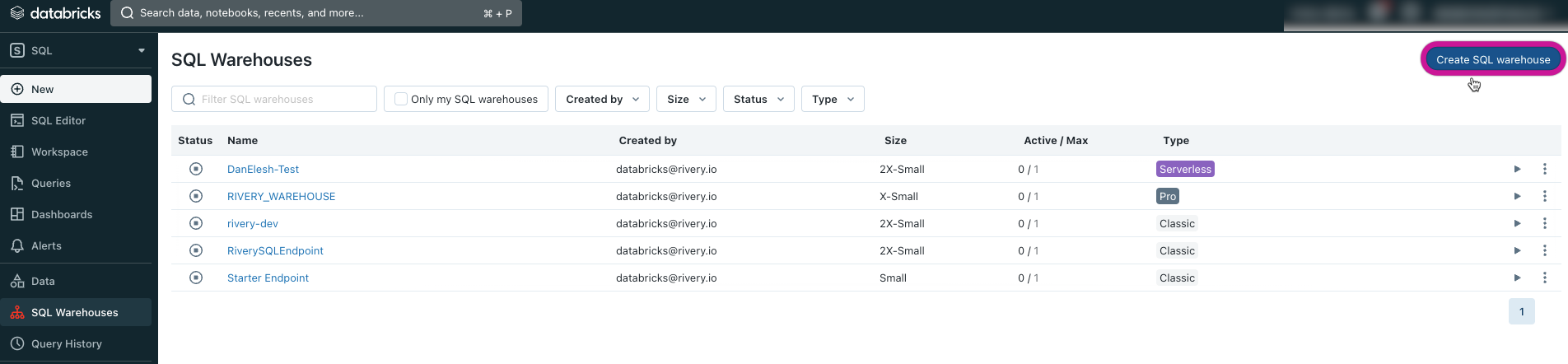
In the modal opened for new SQL endpoint detail, Name your endpoint (for example "RiverySQLEndpoint"), choose the right Cluster Size and set the Auto Stop to at least 120 minutes of no-activity. Click on Create.
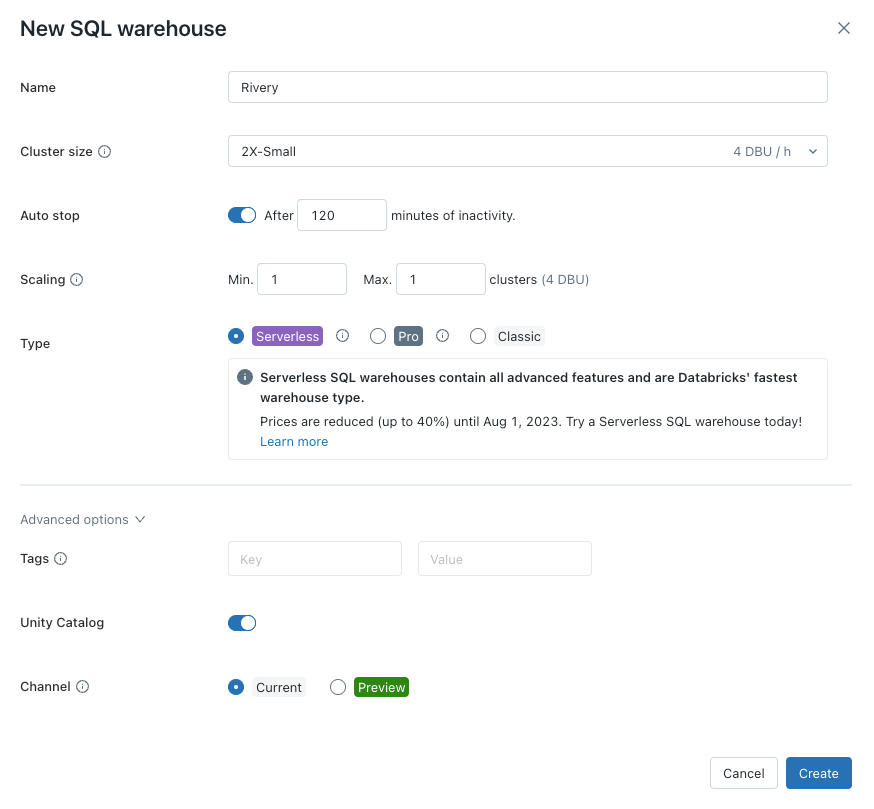
Configure Data Access For the SQL Warehouse
Navigate to the Admin Settings.
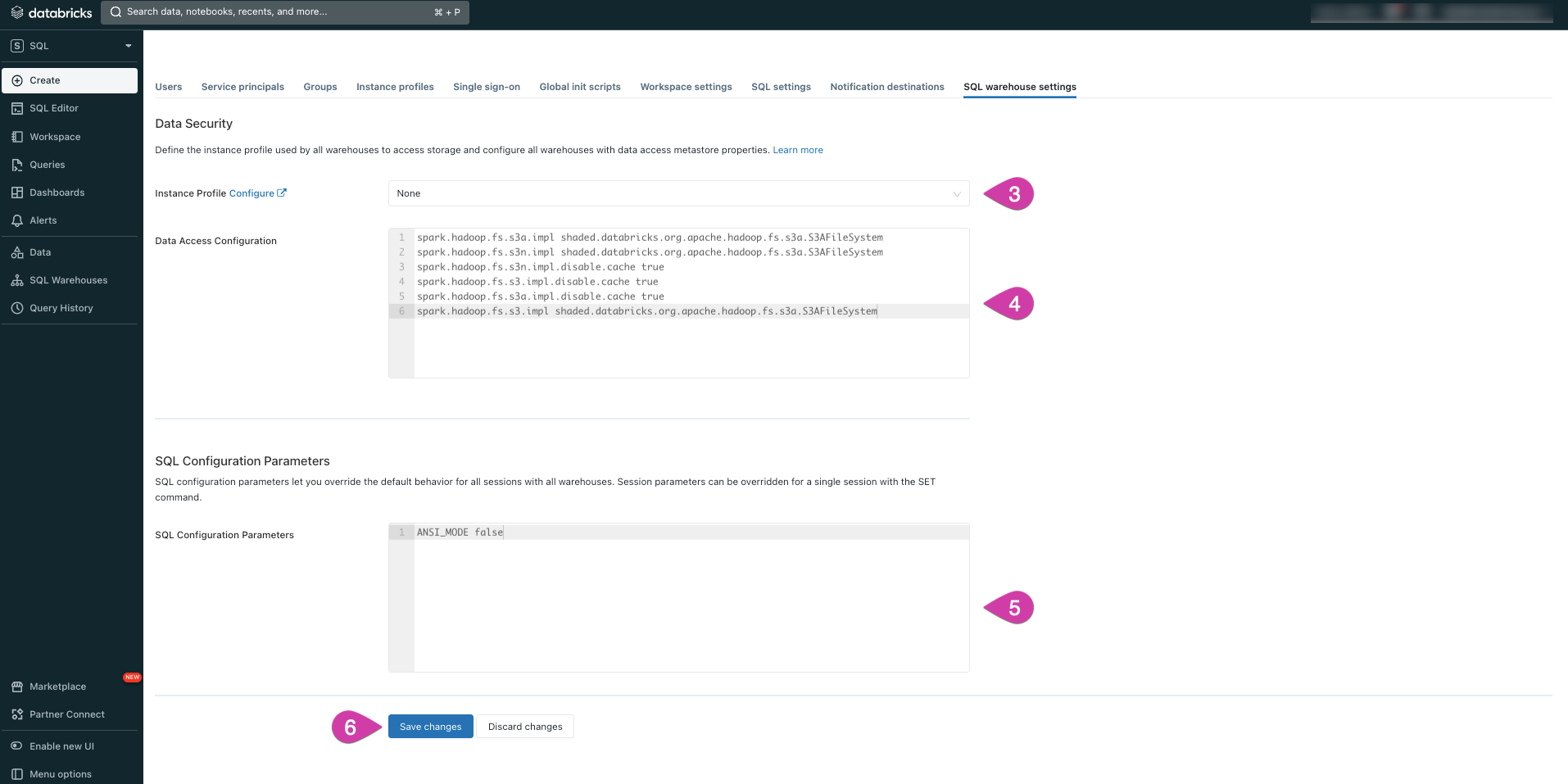
Click the SQL Warehouse Settings tab.

If you are using an Instance Profile, select the specific one that you wish to use.
Copy and paste the following configurations into the designated textbox for Data Access Configuration:
spark.hadoop.fs.s3a.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3n.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem
spark.hadoop.fs.s3n.impl.disable.cache true
spark.hadoop.fs.s3.impl.disable.cache true
spark.hadoop.fs.s3a.impl.disable.cache true
spark.hadoop.fs.s3.impl shaded.databricks.org.apache.hadoop.fs.s3a.S3AFileSystem
- In the SQL Configuration Parameters textbox, configure the following settings:
ANSI_MODE false
- Click Save Changes.
Get the SQL Warehouse Credentials
To ensure compatibility with Rivery, credentials are necessary for each SQL Warehouse configured within the Databricks console. In Rivery, each connection typically corresponds to a single SQL Warehouse.
Return to the SQL Warehouses section and select the warehouse that was recently created.
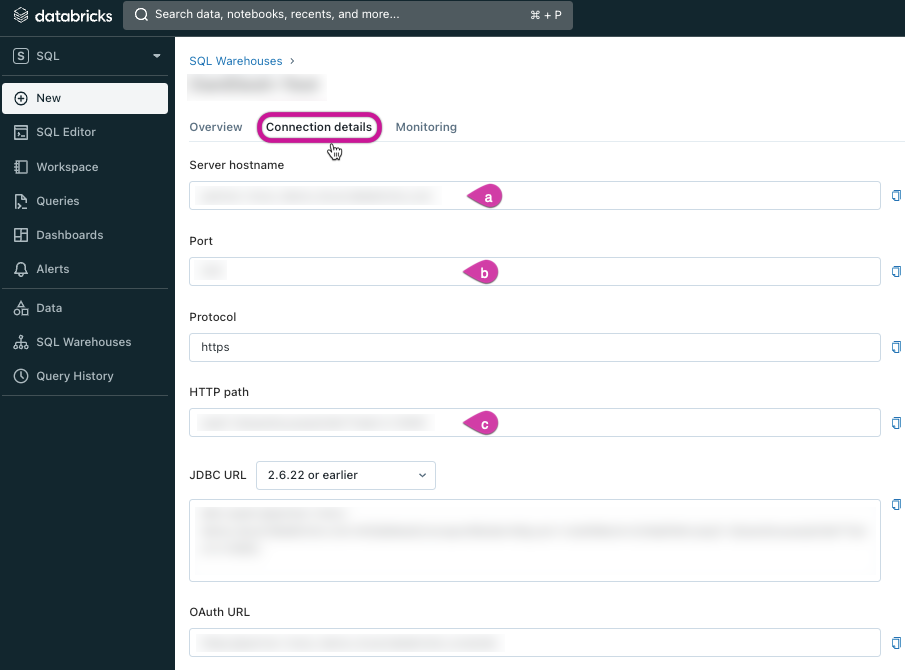
Access the Connection Details tab and copy the following parameters:
- Server Hostname
- Port
- HTTP Path
Create a New Personal Access Token
To establish a connection, it is necessary to generate a Personal Access Token associated with the user. To create a personal access token, please follow the instructions provided below:
Navigate to User Settings.

Click the Access Tokens tab and select Generate New Token.
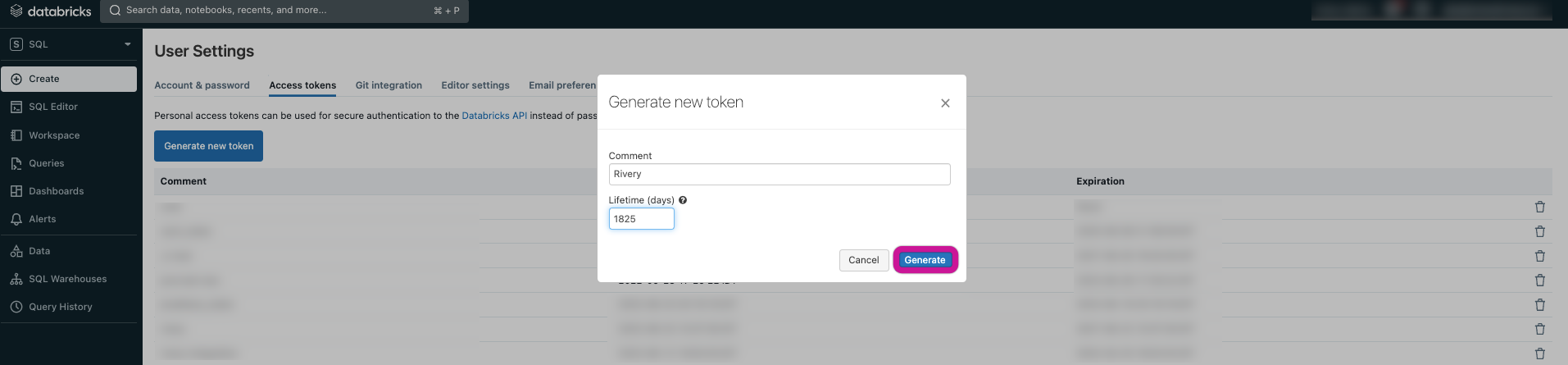
Within the opened modal, provide a name for your token (such as "Rivery") and adjust the expiration lifetime to a duration that guarantees consistent and dependable functionality. In the given instance, we have established an expiration lifetime of 1825 days (equivalent to 5 years).
Configure Databricks to Allow Communication From Rivery Ips (Optional)
If your Databricks workspace has IP restrictions, it is necessary to open the Rivery IPs to ensure the successful execution of any operations from Rivery.
To open the Rivery IPs, follow these steps:
To access the full range of IP access list operations in Databricks, refer to the Databricks documentation on IP access lists.
Submit the following
POSTrequest to the API of your Databricks workspace:
curl -X POST -n \
https://<databricks-instance>/api/2.0/ip-access-lists
-d '{
"label": "Rivery",
"list_type": "ALLOW",
"ip_addresses": [
"52.14.86.20/32",
"13.58.140.165/32",
"52.14.192.86/32",
"34.254.56.182/32"
]
}'
Create a New Databricks Connection in Rivery
Go to Connections, and click on + New Connection button.
Look for Databricks.
Fill in the Connection's Name.
Copy and paste the Server Hostname from the previous steps into the designated field.
Specify the Port value (typically set to the default of 443)
Copy and paste the HTTP Path obtained from the previous steps.
Enter the Personal Access Token.
Indicate your desired Catalog as the default catalog for your Databricks Rivers.
Please note that you can also specify it at the River level.
If you choose not to provide any value for this field, the data will be loaded into the hive_metastore as the default option.Use the Test Connection function to see if your connection is up to the task. If the connection succeeded, you can now use this connection in Rivery.
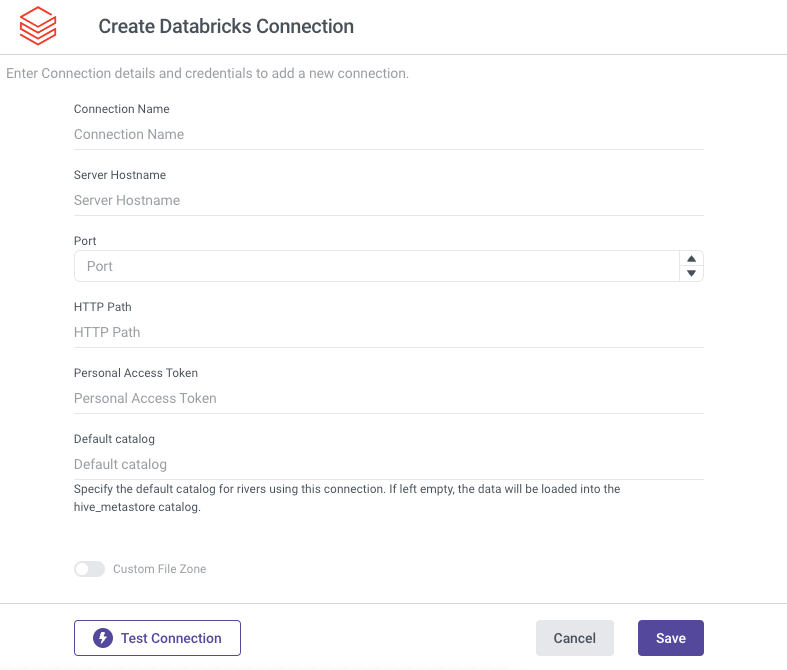
Custom File Zone
A Custom File Zone is a data storage setup enabling organizations to flexibly manage and store their data. Rivery's out-of-the-box Managed File Zone provides this functionality effortlessly, while the Custom File Zone provides organizations with greater authority over the specifics of data storage, although it requires setup.
For additional details on the setup process, kindly refer to our documentation regarding the Custom File Zone.
Was this article helpful?