Settings Tab
- 3 Minutes to read
- Print
- DarkLight
- PDF
Settings Tab
- 3 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
This page outlines the technical specifications and features of the Settings Tab within each River
Overview
The Settings Tab provides users with the ability to set and manage various configurations in Rivers. It provides a centralized location for all settings related tasks, making it easier for users to manage and maintain Rivers.
Working with the Settings Tab
Schedule Me
Once you've configured your River's Column Mapping step, you can either execute it on demand (by clicking Run at the bottom of the screen) or schedule it.
Click 'Schedule Me' under the Settings tab to access the scheduling options:
River scheduling options are tied to specific plans and are detailed in the following manner:
- Starter Plan: Rivers can be scheduled with a minimum interval of 60 minutes.
- Professional Plan: Rivers can be scheduled with a minimum interval of 15 minutes.
- Enterprise Plan: Rivers can be scheduled with a minimum interval of 5 minutes.
Additionally, Professional and higher plans provide advanced scheduling functionalities utilizing custom Cron Expressions.
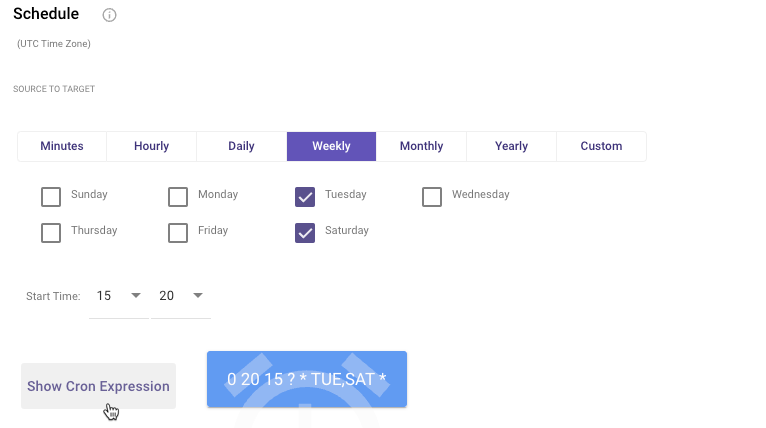
Cron Expression
To set more custom scheduling frequencies, you can use a Cron expression. Rivery utilizes the quartz style format of cron expressions.
The Cron pattern consists of seven space-separated fields:
<second> <minute> <hour> <day of the month> <month> <day of the week> <year>
You can enter your Cron expression under the Custom tab:
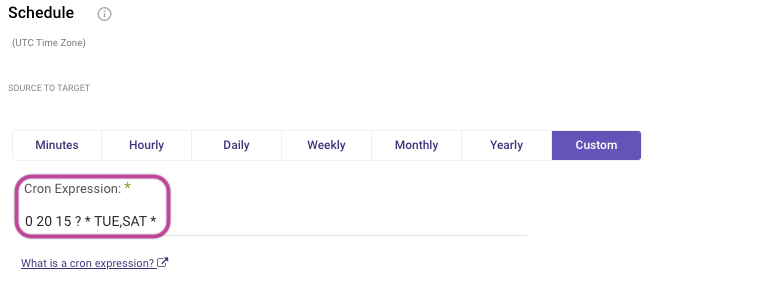
If you'd like to use 'last day of month' syntax, use last instead of L.
For example, if you'd like to schedule the river to run every last day of the month at 22:30 PM, use the following syntax:
0 30 22 last * ? *
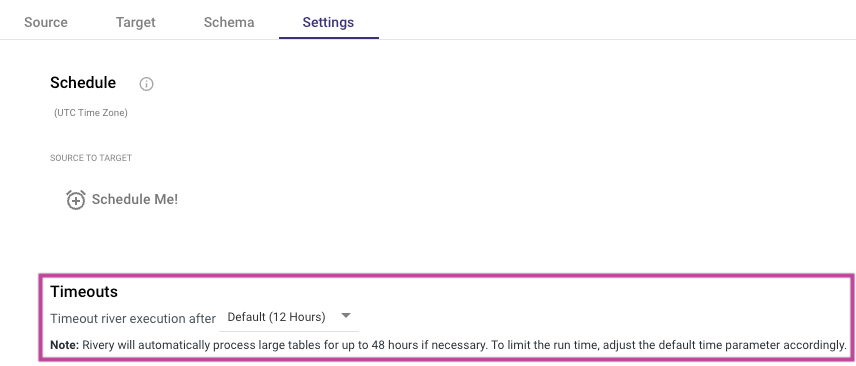
Extended Execution Time for Large Tables and API Reports
Rivery extends the execution time for handling large datasets, including RDBMS tables and API reports. This feature allows Rivers to efficiently process and load extensive data, automatically extending the processing time up to 48 hours if necessary, ensuring successful data loading.
Key Details
RDBMS Tables:
Rivery has an automatic mechanism that adjusts the execution time based on the size of the table or the number of rows. For large tables, Rivery will automatically switch to long-duration mode to complete the process without manual intervention.API Reports:
Rivery predefines certain API reports that typically return large datasets. These reports are automatically configured to run with extended execution time when necessary. Users can adjust the default timeout value in their River’s settings to limit the run time as per their preference.
User Control
You can adjust the default execution time in the River's settings tab to customize the timeout limit. If a custom timeout value is set, the process will terminate after the selected time is exceeded.
Automatic Update to Reports
Rivery will update the list of API reports that require extended execution as new large reports are identified. These reports will be automatically set to use the extended time without user action.
Please Note:
Rivery will automatically process large tables and reports for up to 48 hours, unless the user modifies the default timeout setting.
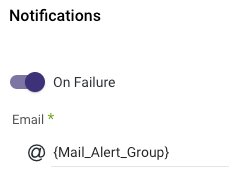
Notifications
If you would like to be notified upon a failure, warning, or when a run-time threshold is reached, simply set one of them to true and enter your email address.
Please Note:
- Since each table functions as a run in the background, an alert will be generated for every unsuccessful run (table). If the user intends to configure an alert for the "no data" indication, they can do so using the checkbox labeled "On Warning".
- To automatically receive River failure notifications in Slack, you can set up a dedicated Slack channel and link it to Rivery’s email alert system. This guide will walk you through the technical steps required to integrate Slack with Rivery.
Sub Rivers
Sub Rivers allow smaller specialized processes to be nested within larger ones. These sub-processes can inherit main River settings or have unique parameters, enhancing flexibility and customization in data processing. Sub Rivers are supported in specific Sources; refer to the Sub Rivers document for details.
Was this article helpful?