Sources
- 6 Minutes to read
- Print
- DarkLight
- PDF
Sources
- 6 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Overview
Rivery connects to your source, retrieves the data, and delivers it to your destination. We offer customers the option to use their own intermediate storage (Custom File Storage) before transferring the data to the specified destination, ensuring that no data is stored on a vendor's servers.
For a detailed guide on constructing simple data pipelines that transfer data from a Source to a Target destination, please refer to our Source to Target River - General Overview document.
Types of Sources
Applications
The data provided by your company's software services can offer greater insight than what is available on their internal dashboards. Many of these services include APIs (Application Programming Interfaces) that can be used to access or extract data from them through a secure internet connection. Riverys creates connections to various applications and then gathers the delta of changes from them at a cadence set by the customers.
Data Extraction Time Variability in APIs
When extracting data from APIs in data sources such as Adobe, LinkedIn, or Facebook, the time required to retrieve a report can vary significantly due to several factors:
API Rate Limits and Throttling
- Rate Limits: Many APIs enforce rate limits to protect their servers from being overwhelmed. Exceeding these limits can slow down response times or limit the number of results returned.
- Throttling: In cases of throttling, the API may return partial data or take longer to fulfill a request, leading to delays.
Server-Side Data Processing
- Data Processing: APIs may need to process large volumes of data (e.g., aggregating, filtering, or calculating metrics) before returning results. This can increase response time, particularly with complex reports or large datasets.
- Request Queuing: Some APIs may queue requests based on system load, further delaying data retrieval.
Data Availability and Latency
- Data Timing: Requested data may not be immediately available, particularly if it relies on near-real-time processing. This can result in incomplete data or delays in reflecting the latest information.
- Inherent Latency: Certain data sources may have built-in latency affecting how quickly data becomes available through their APIs.
Query Complexity
- Complex Queries: Queries involving multiple filters, joins, or custom metrics can take longer to execute. This complexity may cause the API to time out or return a limited subset of the data.
- API Limitations: If the API struggles to process complex queries efficiently, it may result in slower response times or incomplete data.
Network Latency and Connectivity
- Geographic Latency: Network latency, especially when communicating with distant servers, can affect data retrieval speed.
- Connectivity Issues: Poor network connectivity or temporary disruptions can cause delays, partial responses, or incomplete data retrieval due to connection timeouts.
These factors contribute to the variability in the time required to extract data via APIs, and understanding them can help in optimizing the data retrieval process.
Optimizing Data Extraction and Loading Performance
To maximize the efficiency of data extraction and loading, fine tuning the following settings is essential. Each setting plays a role in balancing performance with resource usage.
Exporter Chunk Size:
- The default value is 30,000, which is suitable for most situations.
- For wide tables with many columns or large text fields (JSON/XML/TEXT):
- Lower the chunk size to reduce memory usage and avoid out-of-memory failures. - For narrow tables:
- Consider increasing the chunk size for potentially higher throughput.
Interval Chunk Size:
- This setting is used to split data extraction over long periods or for large amounts of data.
- Options typically include:
- Don't Split (pull all data in one bulk)
- Daily
- Monthly
- Yearly (less recommended)
Best Practices
- For Exporter Chunk Size:
- Test with different chunk sizes, starting at the default (30,000).
- Reduce the size if you encounter memory-related errors.
- Increase the size for narrow tables to maximize throughput.
- For Interval Chunk Size:
- Use interval splitting for high-volume data or long timeframes.
- Balance performance with API rate limits by selecting an appropriate interval.
- Ensure the date column is included in the extraction results to align data with interval boundaries.
- For Exporter Chunk Size:
Databases
Customers can extract data from databases and move it to a Data Warehouse. Rivery can connect to both on-premise and cloud databases, and clients can use Whitelisted IPs and SSH Tunnels to secure the connection.
Our Incremental Data Capture method is dependable, secure, and cost effective thanks to our exclusive Change Data Capture functionality method for databases.
Events
Rivery's solution allows to collect data via a webhook. A webhook is an HTTP callback that is triggered by a user-defined event on your website or in your application. A webhook allows you to send real-time HTTP notifications from one application to another when an event that you define occurs. At a webhook URL, JSON elements are received as HTTP POST requests.
Files
Rivery offers the ability to sync files from On-Premise and Cloud storage sources.
Rest API
Users can connect to any API Endpoint that includes an authentication flow.
Data from an Action River can be loaded into a target table in your cloud database using Rest API.
Stages of Release
We release connectors (Sources and Targets) in a staged manner to ensure we deliver the highest quality experience to our users. Below, we have detailed what users can anticipate at each stage of the release:
| Stage | Definition |
|---|---|
| Beta | The Beta Stage in Rivery is characterized by a controlled release where the connector is live but might have a limited set of its total capabilities. The primary objective during the Beta stage is to test the connector in a range of uncommon and complex scenarios (edge cases) to ensure stability and readiness for a wider release. |
| Alpha | The Alpha Stage of Rivery's release lifecycle is designated for connectors that are at a preliminary stage of development and are primarily undergoing a testing phase. Users who are interested can manually request access. |
| Coming Soon | The Coming Soon Stage denotes a preliminary stage in the development of Rivery's product, indicating that the connectors in this stage have been officially added to Rivery’s short term roadmap. Users may request early access when it becomes available. |
| Sunset | The Sunset Stage at Rivery is initiated when a connector is phased out following the announcement by the data source vendor that the service has reached its end of life stage. |
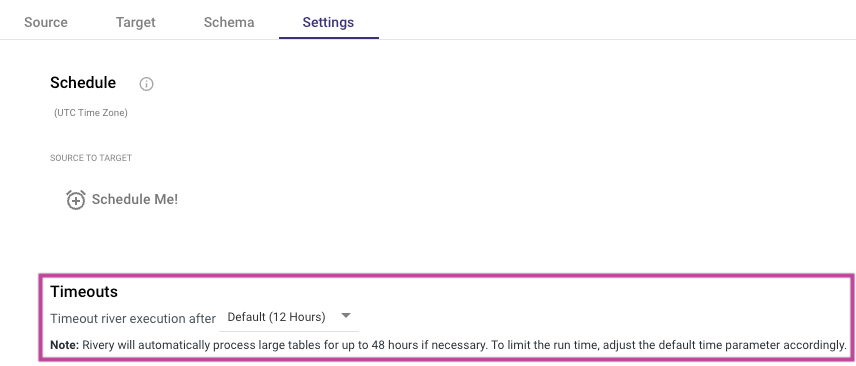
Extended Execution Time for Large Tables and API Reports
Rivery extends the execution time for handling large datasets, including RDBMS tables and API reports. This feature allows Rivers to efficiently process and load extensive data, automatically extending the processing time up to 48 hours if necessary, ensuring successful data loading.
Key Details
RDBMS Tables:
Rivery has an automatic mechanism that adjusts the execution time based on the size of the table or the number of rows. For large tables, Rivery will automatically switch to long-duration mode to complete the process without manual intervention.API Reports:
Rivery predefines certain API reports that typically return large datasets. These reports are automatically configured to run with extended execution time when necessary. Users can adjust the default timeout value in their River’s settings to limit the run time as per their preference.
User Control
You can adjust the default execution time in the River's settings tab to customize the timeout limit. If a custom timeout value is set, the process will terminate after the selected time is exceeded.
Automatic Update to Reports
Rivery will update the list of API reports that require extended execution as new large reports are identified. These reports will be automatically set to use the extended time without user action.
Please Note:
Rivery will automatically process large tables and reports for up to 48 hours, unless the user modifies the default timeout setting.