SQL Server Change Tracking
- 6 Minutes to read
- Print
- DarkLight
- PDF
SQL Server Change Tracking
- 6 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Overview
Change Tracking captures the fact that rows in a table have changed, but does not capture the data that was changed or how many times a row has been change. This enables applications to determine which rows have been changed and when that change occurred. Therefore, Change Tracking is more limited in the historical questions it can answer compared to Change Data Capture. However, for those applications that do not require historical information, there is far less storage overhead because the changed data itself is not captured.
Change Tracking saves the change information by saving the primary key column of each row that was changed. It saves a version number for each INSERT/UPDATE/DELETE operation. To obtain the latest data for changed rows, an application can use the primary key column values to join the source table with the tracked table. In each execution, the application can track the latest changes by version numbers.
How does Change Tracking Extraction work in Rivery?
In order to align the data and the metadata in the first run, Rivery makes a migration of the chosen table(s) using the Overwrite loading mode. After the initial migration completes successfully, Rivery saves the database's current change tracking version in the river settings. The following river executions will extract data from this version until the newest version at the current execution time, and load the data using the Upsert-Merge loading mode to the target table(s).
Enable Change Tracking for Tables
To track changes, change tracking must first be enabled for the database, and then enabled for the tables that you want to track within that database. The table definition does not have to be changed in any way, and no triggers are created.
To enable change tracking for a DB, use the following ALTER operation:
ALTER DATABASE AdventureWorks2012
SET CHANGE_TRACKING = ON
(CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) To enable change tracking for a specific table, use the following ALTER operation:
ALTER TABLE Person.Contact
ENABLE CHANGE_TRACKING You can find more information regarding change tracking settings in Microsoft SQL Server docs.
Initiate Migration
To initiate migration, follow these steps:
Go to the "Schema" tab.
Select the desired table.
Click on "Table Settings."
Scroll down and check the "Initiate Migration" checkbox.
By default, this process also overwrites the table to align the SQL Server database with the corresponding Snowflake or Databricks table (optional).

Using Change Tracking
Select the Change Tracking option in the Source tab:
Before initiating the first river execution, verify that all tables are marked as "Initiate Migration" within the Table Setting tab found in the Schema section.
This will extract all the source table's data into your target table and synchronize the river with the DB last change tracking version.
The following executions will extract data from the last synchronization version until the database's current version.
In the Activities tab you can find which versions were extracted for each execution:
Hard Delete
Microsoft-SQL Change Tracking with Snowflake and Databricks Target Rivers features our 'Include Deleted Rows' functionality.
This option allows you to keep track of data that has been deleted from a source table.
To activate "Include Deleted Rows", follow these steps:
1. In Microsoft SQL Server River, click on Schema.
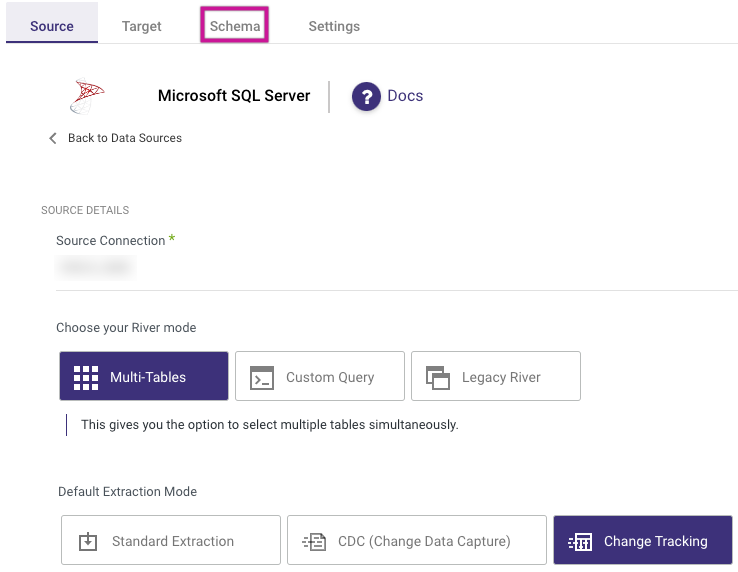
2. Choose a dedicated Source Table.
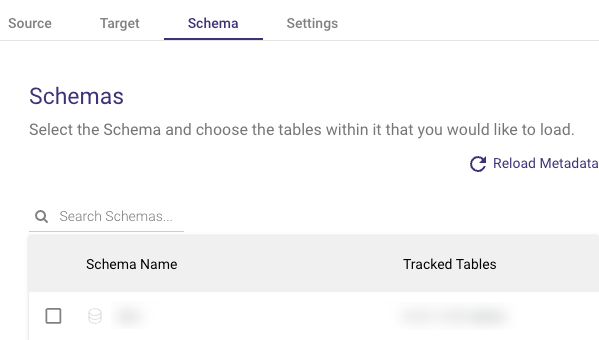
3. Select Table settings.
4. Check Initiate Migration, and then Overwrite Table Migration to match the existing database in SQL Server with the Snowflake/Databricks table (optional).
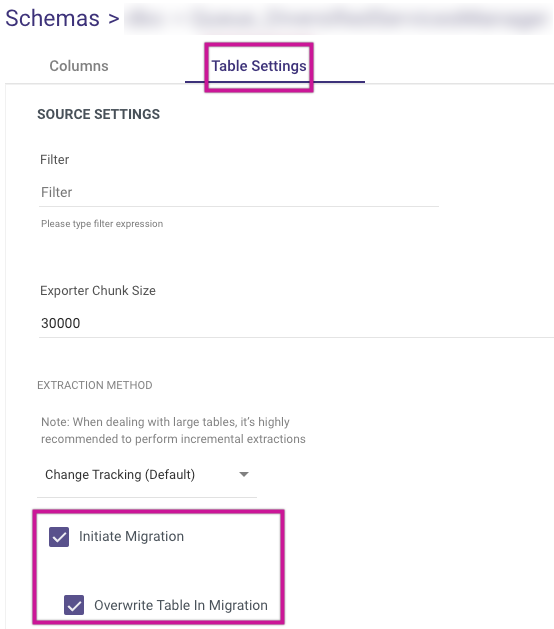
NOTE:
Skip this step if you want to keep working with the data in Snowflake/Databricks that has been marked as deleted.
After the first Initiate Migration is completed, The checkbox is de-checked.
5. Click Include Deleted Rows.
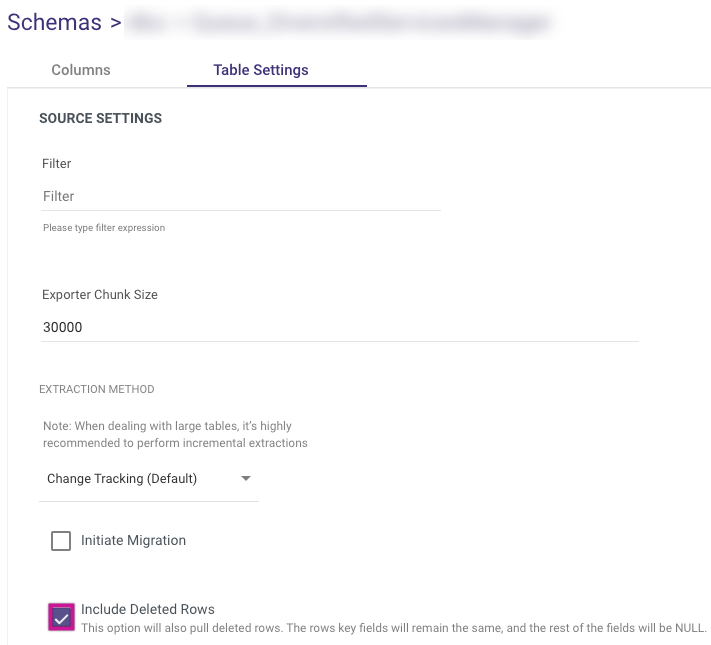
NOTE:
If 'Include Deleted Rows' is selected, the River will retrieve all changes from the Change Tracking table, including deleted rows.
It also adds a '__DELETED' column to indicate if the row was deleted or not from the source table.
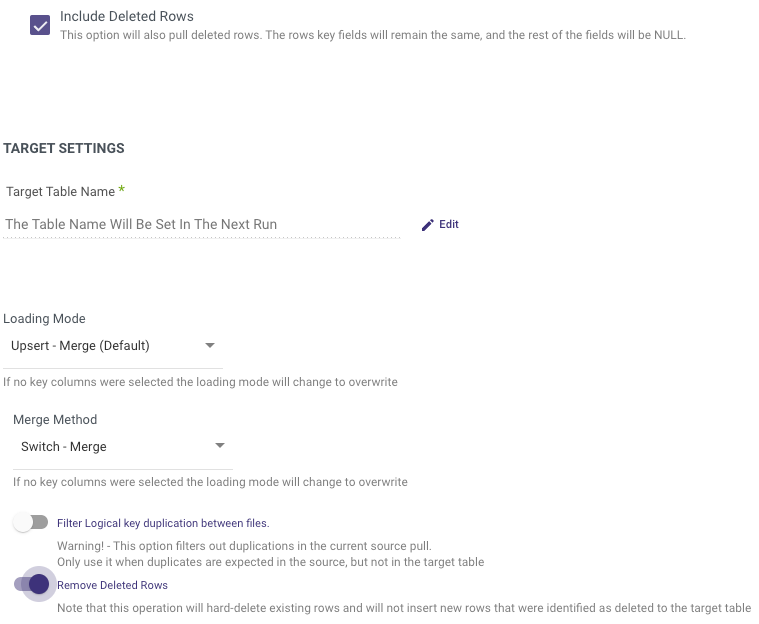
6. Enable Remove Deleted Rows (optional).
NOTE:
This option is permitted only by selecting 'Upsert - Merge' in Loading Mode, as seen here:
WARNING:
By enabling 'Remove Deleted Rows', all rows having the status 'True' (Deleted) will be eliminated and removed from Snowflake/Databricks Target table.
7. Click Run.
8. Connect to Snowflake or Databricks to access and view the results.

Troubleshooting
Data Restore
When any database restore operation is made for a table, please check the “Initiate Migration” checkbox to initialize the table after the restore operation. This will load all the data from the source table into the target table to make sure it's synchronized and to prevent data loss.
Cleanup During River Extraction
While the data is being extracted, a database cleanup process may remove change tracking data that is older than the designated retention period.
By the time the changes are obtained, the most recent synchronization version might no longer be valid. Therefore, an error will pop up - "Min valid version is greater than the last synchronization version. Please reinitialize the table".
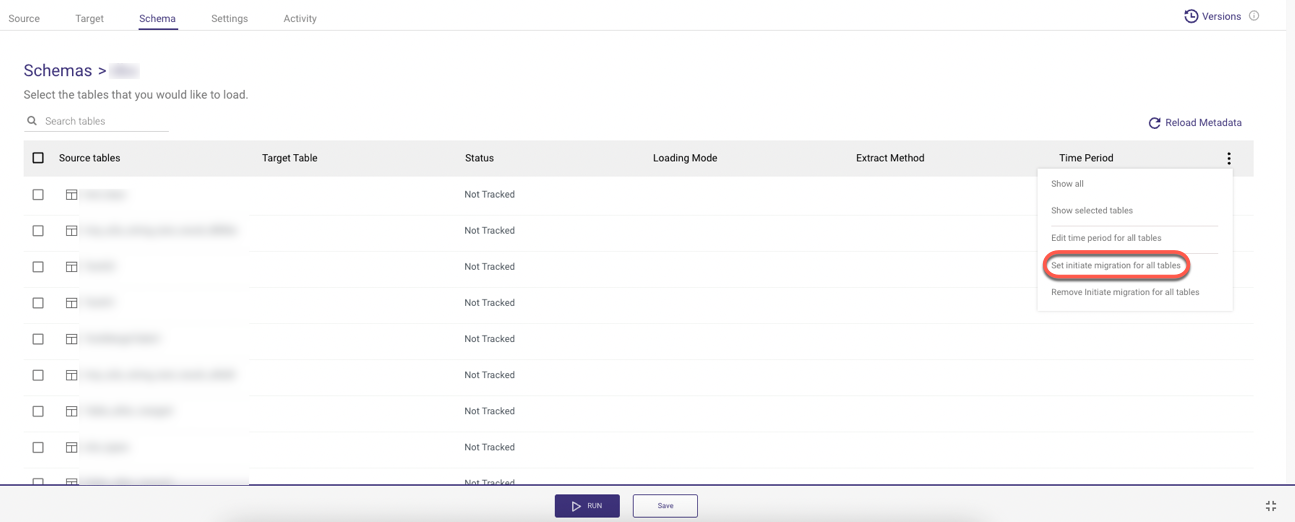
To re-initialize the table, navigate to your River's Schema and choose "Set initiate migration for all tables" from the 3 dots menu.
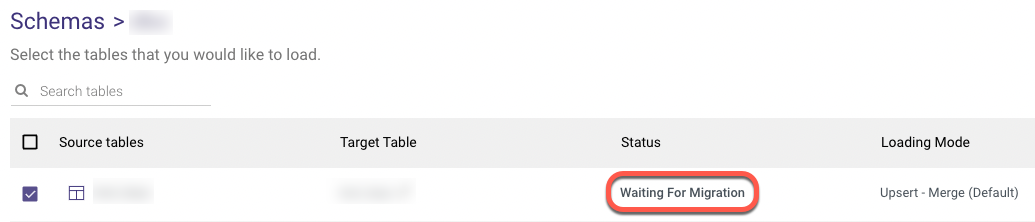
All of the tables you've chosen should have the status "Waiting For Migration," which denotes that your synchronization version has been reset.
Verifying Change Tracking Status
To verify if Change Tracking is enabled for a database and its tables in SQL Server, you can execute the following queries:
Check Change Tracking for Databases
SELECT
d.name,
ctd.*
FROM
sys.change_tracking_databases ctd
JOIN
sys.databases d
ON d.database_id = ctd.database_id;
Check Change Tracking for Tables
SELECT OBJECT_NAME(object_id) AS TableName,
is_track_columns_updated_on AS ChangeTrackingEnabled
FROM sys.change_tracking_tables
WHERE OBJECT_NAME(object_id) = 'YourTableName';
These queries will help you determine whether Change Tracking is enabled at both the database and table levels in your SQL Server environment.
Cleanup During River Extraction
[RVR-MSSQL-RDBMS-301]: Last synchronization version doesn't exist for this table.
Please reinitialize the table data.
Please refer to our docs: Page - 'SQL Server Change Tracking'. Section - 'Cleanup During River Extraction'This issue arises due to the absence of the last_sync_version. If there's no last sync version detected, we trigger an error message and must reset the table to ensure we can access change tracking data. This situation can occur because of automated cleanup processes, which may happen either frequently or infrequently depending on certain factors.
The occurrence of this issue may stem from excessive cleanup, potentially leading to synchronization problems. To address this, we should examine the logs for any indications of issues related to change tracking or the cleanup process in the MSSQL server logs. After resetting and running the river, it's crucial to monitor the logs closely during subsequent runs to catch any recurrence of this error message.
Understanding how the change tracking tables are used is also essential. Automatic resets can occur due to various factors, including the frequency of updates and deletions in the tables.
Questions to consider are:
Is there a high volume of update and delete operations without corresponding inserts in this table?
Is the version column updated or deleted frequently?
Are there concurrency issues, such as multiple processes attempting to synchronize with change tracking simultaneously, especially if this table serves purposes beyond just this river? Proper coordination of the synchronization process is necessary to prevent such issues.
How to Find Changes for Relevant Version for a Table?
In some cases, you may need to retrieve either the latest or the initial change tracking version. This will help determine if your river is going out of sync due to the purging of the minimum valid version in the database.
To fetch the minimum valid version:
// CHANGE_TRACKING_MIN_VALID_VERSION (Transact-SQL) - SQL Server
SELECT CHANGE_TRACKING_MIN_VALID_VERSION(OBJECT_ID('[<schea_name>].[<table_name>]')); To fetch the current (latest) version on the server:
// CHANGE_TRACKING_CURRENT_VERSION (Transact-SQL) - SQL Server
SELECT CHANGE_TRACKING_CURRENT_VERSION()To retrieve changes since a specific version:
// CHANGETABLE (Transact-SQL) - SQL Server
DECLARE @last_sync_version bigint;
SET @last_sync_version = <value obtained from query>;
SELECT *,
SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION,
SYS_CHANGE_COLUMNS, SYS_CHANGE_CONTEXT
FROM CHANGETABLE (CHANGES <schema>.<table_name>, @last_sync_version) AS C;To get all current rows with their associated version:
// CHANGETABLE (Transact-SQL) - SQL Server
// Get all current rows with associated version
// This is using CHANGETABLE(VERSION) option in SQL Server
SELECT t.*
c.SYS_CHANGE_VERSION, c.SYS_CHANGE_CONTEXT
FROM <tbl_name> AS t
CROSS APPLY CHANGETABLE
(VERSION <table_name>, ([<primary_key_col>]), (t.[<primary_key_col>])) AS c;Was this article helpful?