Amplitude Walkthrough
- 1 Minute to read
- Print
- DarkLight
- PDF
Amplitude Walkthrough
- 1 Minute to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Introduction
Amplitude is a product analytics platform for web and mobile. Here are the instructions about pulling its data into any Target in Rivery.
Prerequisites
- Amplitude Connection. If you don't have one already, you may create it using Amplitude Connection page .
- Organization Admin or Manager permissions in Amplitude.
Pulling data from Amplitude
Choose the Amplitude connection.
Choose Report.
For now, Rivery can fetch data using the Raw Events report only in Amplitude River.
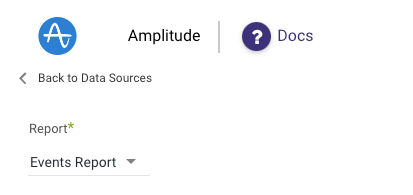
Events Report
The Events report may also have data about Event Properties and User Properties on each event.
Events report based on running data by dates.
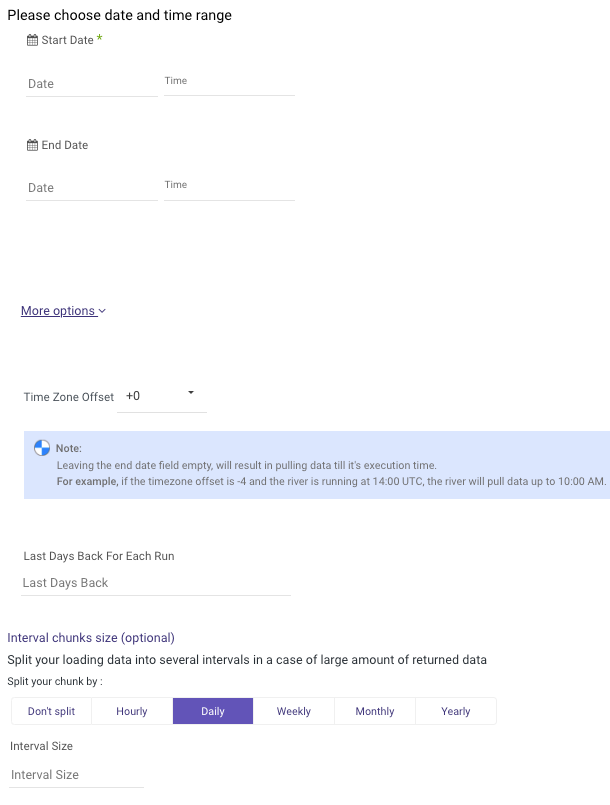
Therefore, Set the Time Period for the report.
Rivery manages the increment for the Rivers, and knows how to fetch incremental data from the source.
Time Period
If Custom Range was chosen, please define the Start Date in order to run the river. When not setting an End Date , Rivery assumes it will run to the current date of which the run was executed.
Moreover, Rivery will use the next end date, as the next Start Date, in the next run.
Interval Chunks - Rivery can run over the increment using chunks, in order to make the loading more efficient and more precise. The available chunk options are:
- Don't Split - Rivery will pull the data from the chosen start date to the end date in one bulk.
- Hourly - The river will be chunked hourly from the start to the end date.
- Day - The run will be chunked daily from the start to the end date.
- Week - The run will be chunked weekly from the start to end date.
- Monthly - The run will be chunked monthly from the start to end date.
Interval Size - User can also define the interval chunk size.
For example, if a 3 hours chunk wanted, set the Interval Chunks to Hourly and the Interval Size to 3.
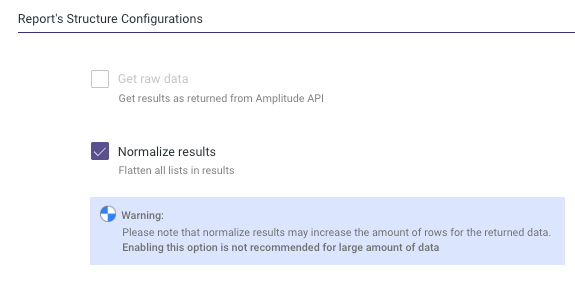
Reports Structure Configuration
You have the option to normalize the results. However, doing so may increase the number of rows in the returned data. It is not recommended to enable this option for large datasets.
Was this article helpful?