Azure Blob Storage Walkthrough
- 1 Minute to read
- Print
- DarkLight
- PDF
Azure Blob Storage Walkthrough
- 1 Minute to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
This provides a general description of Azure Blob Storage and its capabilities.
Introduction
Azure Blob storage is Microsoft's cloud object storage solution. Blob storage is designed to accommodate large amounts of unstructured data. Unstructured data is data that doesn't adhere to a particular data model or definition, such as text or binary data.
Source Details
Connection
To connect Azure Blob storage with your destination, follow our step-by-step tutorial.
Choose a Source connection after you've created a connection, as seen here:
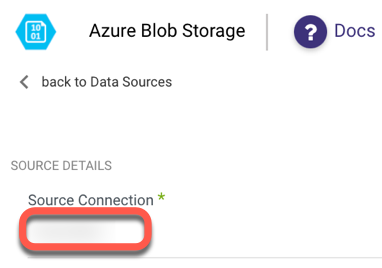
Container Name
After you've created a Container, click the curved arrow next to Container Name on the right side of the row to select a name from the drop down list:
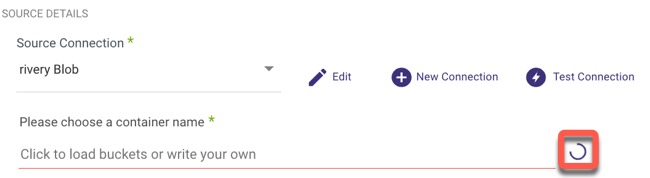
Extraction Modes
In Azure Blob storage, there are 3 types of extraction modes:
- All
- Incremental load by file modified timestamp.
- Incremental run: by template.
All
Choose 'All' to retrieve all data regardless of time periods.
Incremental load by file modified timestamp
Incremental Load by File Modified Timestamp allows you to control the date range of your data:
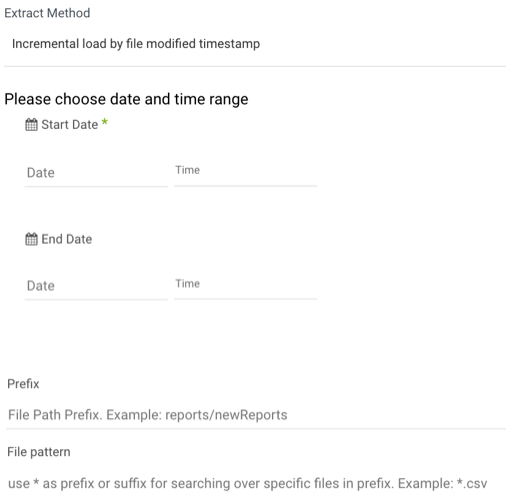
Note:
- Start Date is mandatory.
- Data can be retrieved for the date range specified between the start and end dates.
- If you leave the end date blank, the data will be pulled at the current time of the river's run.
- Dates timezone: UTC time.
Incremental run: by template
Templates allow you to run over folders and load files in the order in which they were created.
Simply choose a template type (Timestamp or Epoc time) and a data date range:
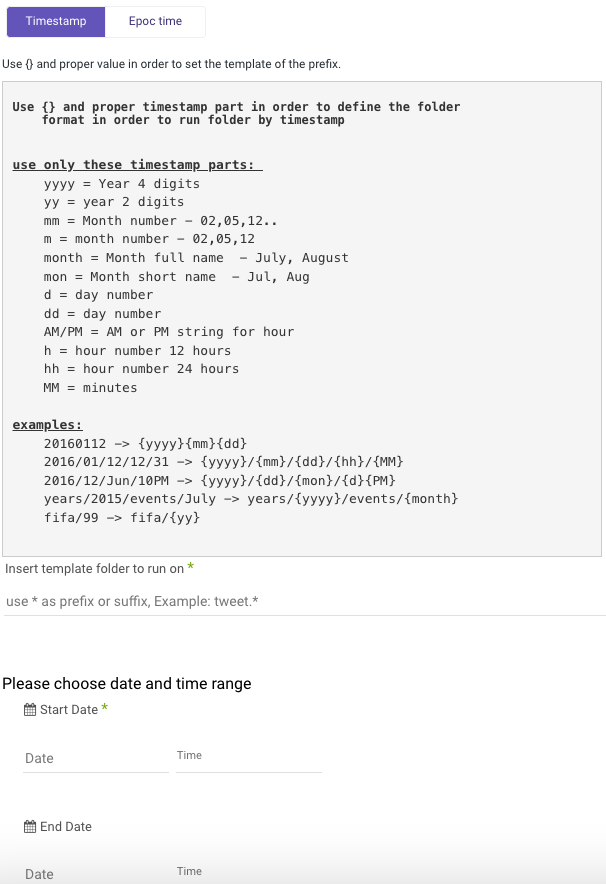
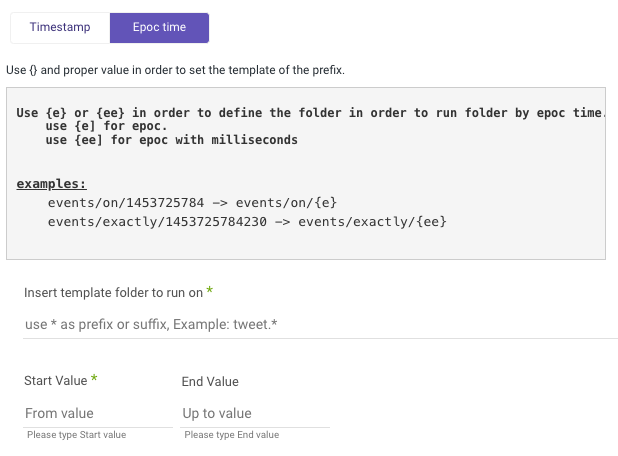
Note:
- Start Value is mandatory.
- Data can be retrieved for the date range specified between the start and end values.
- If you leave the end date blank, the data will be pulled at the current time of the river's run.
- Dates timezone: UTC time.

Note:
- Splitting the requests into smaller chunks may improve the performance of the connection and reduce the time it takes to pull the data.
- You'll need to pull the date column to figure out when each record in the results was created.
Was this article helpful?