Datastore Walkthrough
- 2 Minutes to read
- Print
- DarkLight
- PDF
Datastore Walkthrough
- 2 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Introduction
This document outlines the various methods available in Rivery for extracting data from Datastore, a NoSQL document database provided by Google Cloud Platform. Rivery facilitates the extraction process through two primary methods:
Query by Kind and Query by GQL (Google Query Language).
Additionally, it provides functionalities for mapping attributes to control how data is pulled from Datastore.
Query by Kind
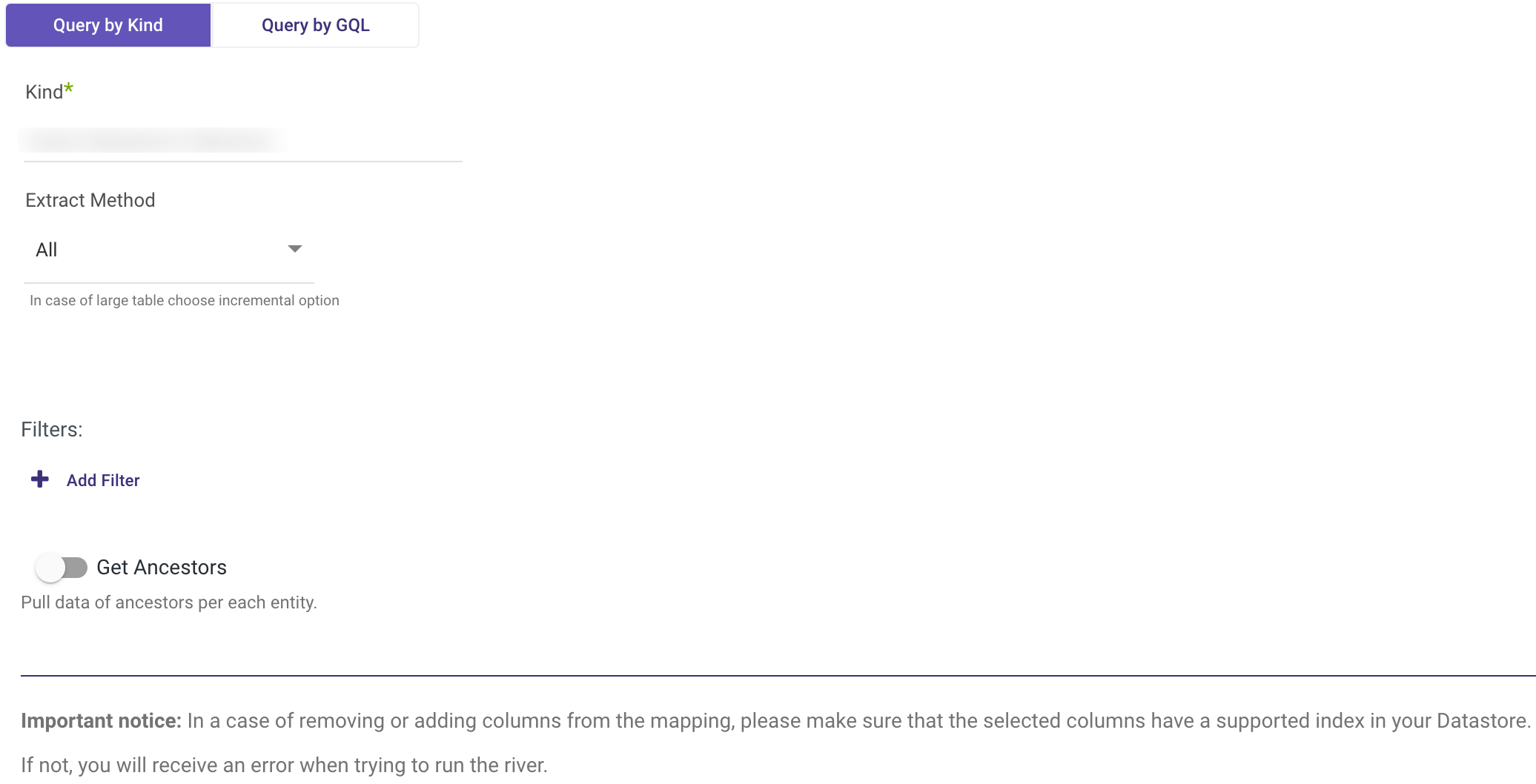
The Query by Kind method resembles the Datastore console, allowing users to browse and extract data from a specified kind in Datastore. It offers options for extracting all available data or utilizing an incremental approach.
Extraction Steps
Kind: Insert the exact name of the kind from which data is to be extracted. The name is case sensitive.
Extract Method
Users can choose between:
All: Pulls all available data from the selected kind.
Incremental: Pulls data based on specified increments.
If selecting Incremental:
- Timestamp: If the field is a standard timestamp field in Datastore.
- Epoch: If the field is an Integer field representing epoch time.
Incremental Field: Filter data by this field. Ensure the field is indexed in the selected Datastore kind to enable filtering.
Incremental Type: Choose between Timestamp or Epoch.
Start Date & End Date: Select the datetime range. Leaving it empty pulls data until the current moment. Use "Include end value" if pulling data until a specific end datetime is necessary.
Interval Chunks Size: Utilize this for pulling large amounts of data to reduce the load on Datastore in each request.
Filters: Add filters based on indexed columns to further refine the data extraction.
Get Ancestors: Optionally retrieve ancestors' information for each entity in the results.
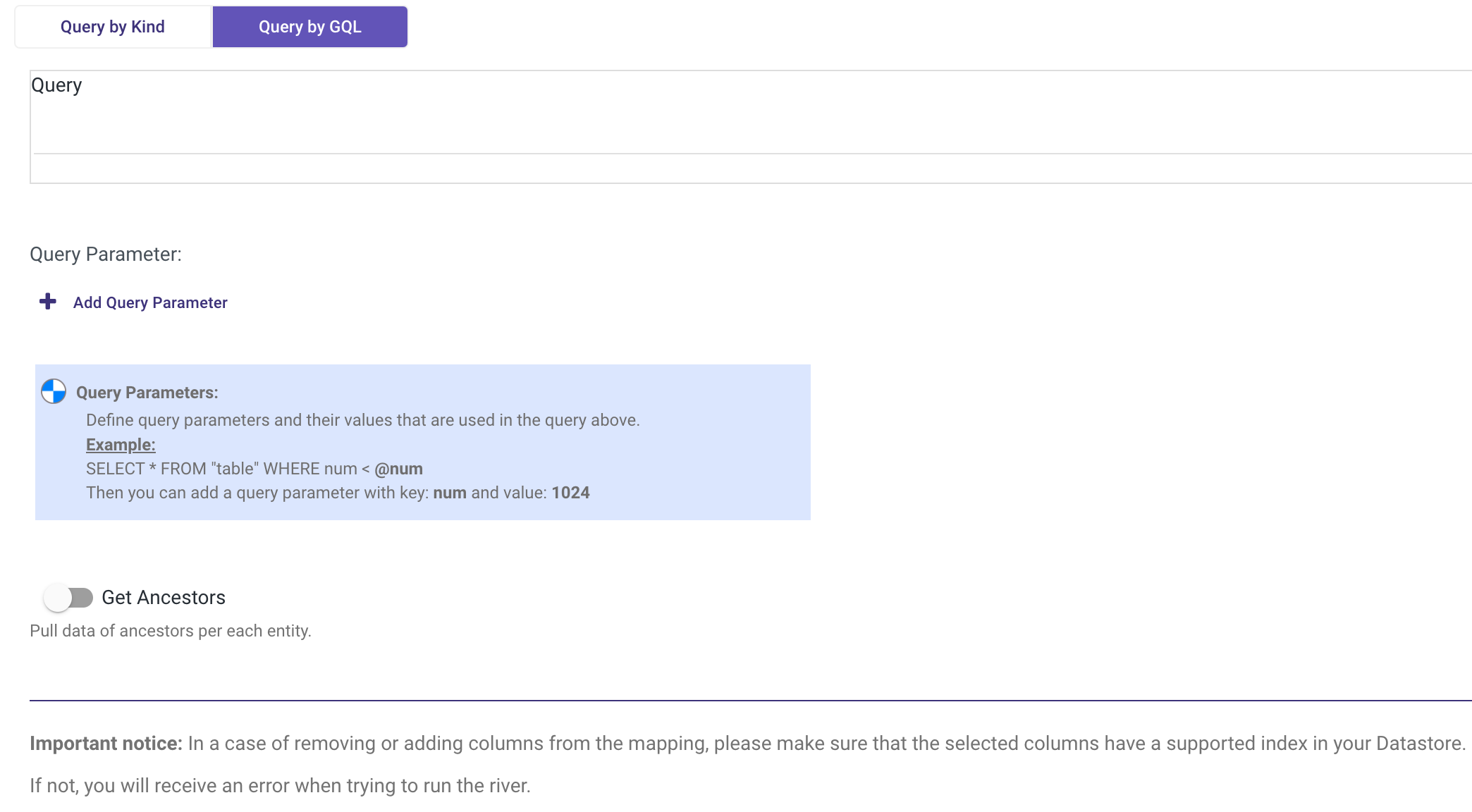
Query by GQL
The Query by GQL method employs Google Query Language for retrieving and manipulating data in Datastore. Users can specify criteria for data selection and manipulation through GQL queries.
Extraction Steps
- Include query parameters for criteria specification.
- Enter the query in the designated text box.
- Optionally toggle to retrieve data ancestors per each entity.
Please Note: Incremental extraction is not supported with GQL.
Mapping Attributes
Mapping attributes control how Rivery pulls data from the selected Datastore kind, offering flexibility in data handling.
Attribute Mapping Steps
- Get Attributes Mapping of Data:
- Click on auto mapping to retrieve column details.
- Ensure required columns are included in the mapping results.
- Convert Data Types:
Change data types of selected columns as needed.
Useful for resolving mapping errors or mismatches.
- Select Columns:
- Modify column selection to pull only required data.
- Ensure selected columns have appropriate indexes in Datastore.
Please Note: After any changes in attribute mapping, refresh the mapping of the Target table to synchronize changes.
Was this article helpful?