Jira Walkthrough
- 4 Minutes to read
- Print
- DarkLight
- PDF
Jira Walkthrough
- 4 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Currently supported:
Rest API - Version 3
Rest Agile API - Version 1
Introduction
Integrating Jira with Rivery enhances project management by automating data-related tasks. Jira handles project tracking, analysis, and reporting, resulting in improved efficiency.
Connection
To connect Jira with your destination, follow our step-by-step tutorial.
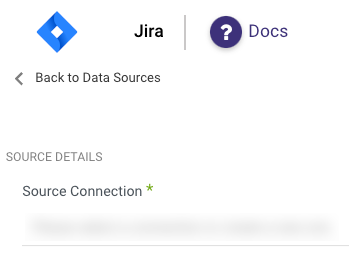
Choose a Source connection after you've created a connection, as seen here:
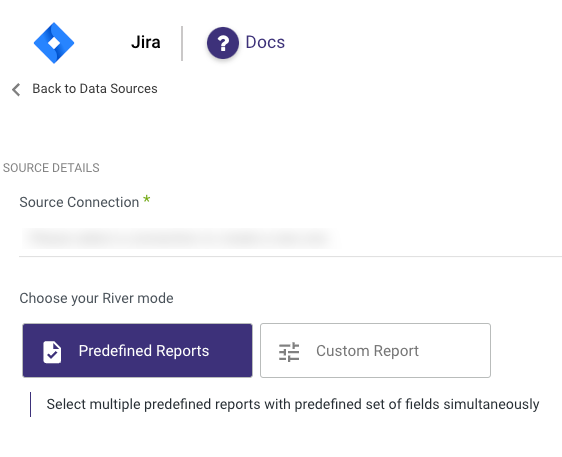
Predefined Reports
Rivery provides a convenient entry point and recommended approach for accessing a range of predefined reports for your use. Each report includes a concise data description, a list of customizable fields (if applicable), and the schema mapping.
Since these reports follow a standardized format, specific fields are restricted and can only be accessed through Custom Reports.
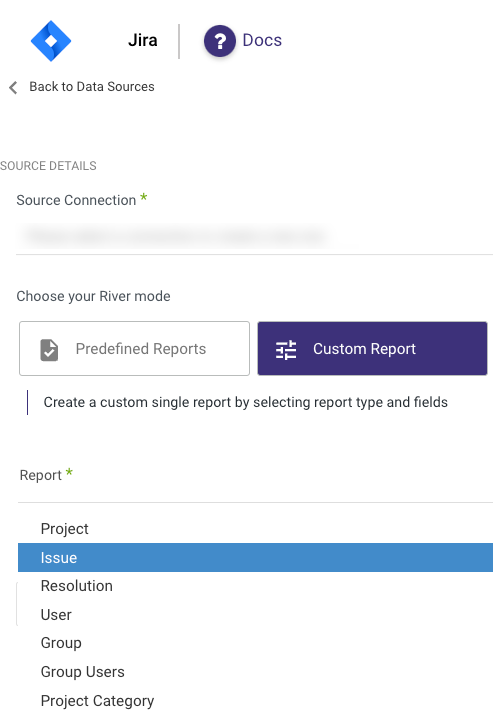
Custom Reports
Select a specific report to pull data from the Jira.
The following image provides an overview of the various custom reports:
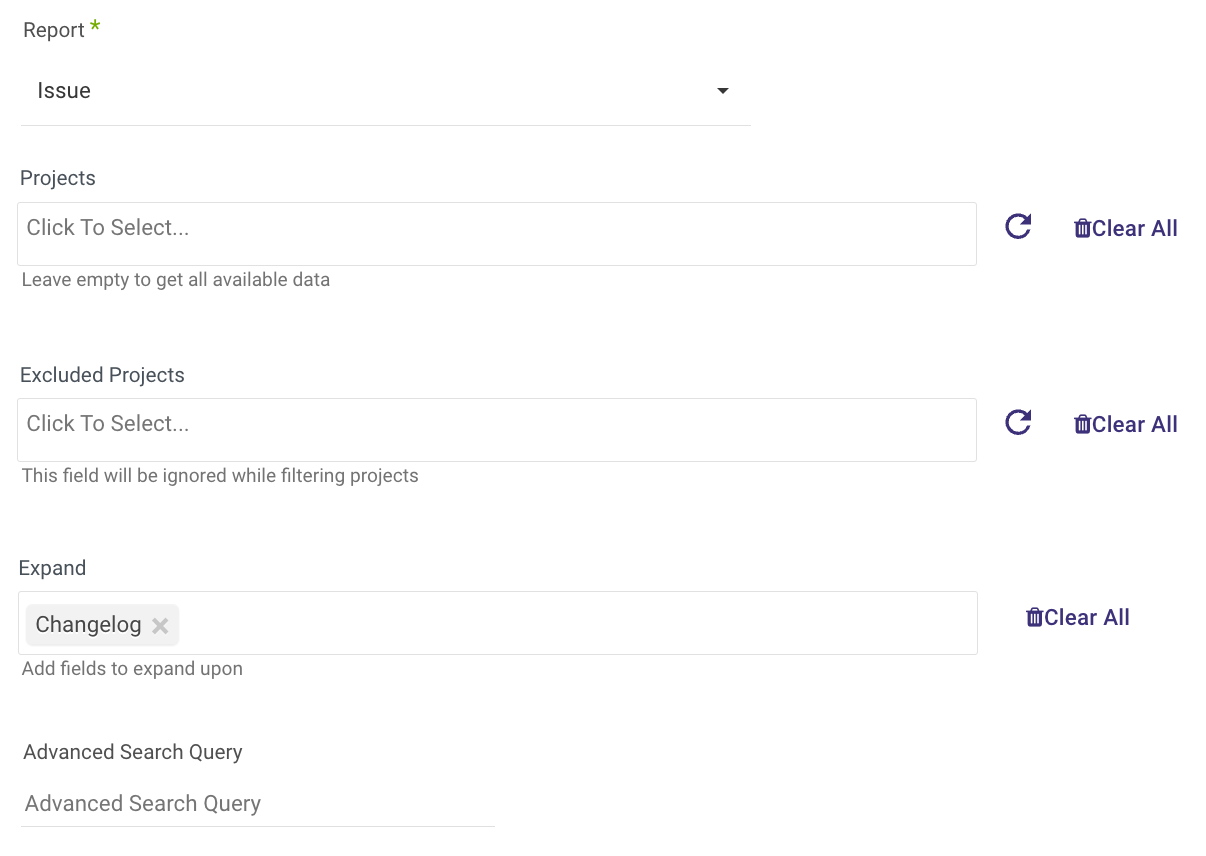
Issues
The Issues report allows you to extract all issues from a given project/s
(Optional) Choose specific projects for issue extraction, or leave this blank to include issues from all projects.
(Optional) To exclude certain projects while extracting all other issues, select these projects under the "Excluded Projects" section.
(Optional) To add an extra field to the report, utilize the expansion option.
(Optional) The report supports Jira Query Language, allowing you to include additional filters under "Advanced Search Query". Note that these filters will be combined using an "AND" clause.
Select a Time Period. The report's time frame aligns with the JQL updatedDate. Refer to the Time Period section for more details.
Please Note:
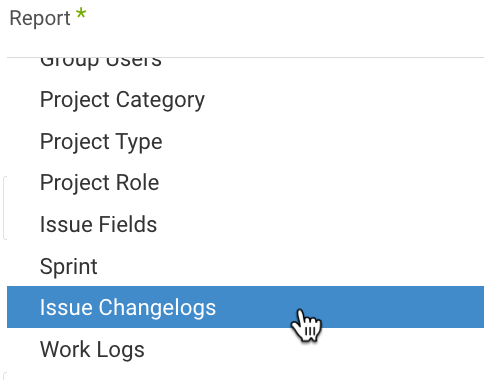
In cases where you expect to gather a significant volume of expanded changelogs in the Issues report, we highly advise choosing the 'Issue Changelogs' report (exclusive to Jira Cloud services) from the dropdown menu. This report will retrieve any additional fields you have selected. To view both the issues and the expanded information, simply merge the Issues and Issue Changelogs reports data in your Target.
Resolution
The resolution report returns a list of all issue resolution values. This is a dimension.
User
The user report returns all the users in your Jira account.
emailAddress
A user's email column (emailAddress) will have an email address value for users whom set their profile privacy settings so that email address is public. Otherwise, this column will get a null value.
Project
The project report returns all the projects in your Jira account.
Project Categories
The project categories report returns all the project categories in your Jira account.
Project Type
The project type report returns all the project types in your Jira account.
Project Rule
The project rule report returns all the project rules in your Jira account.
You can filter the which project rules to return with the project input or leave empty for all projects.

Time period
Relevant for the following reports: Issues.
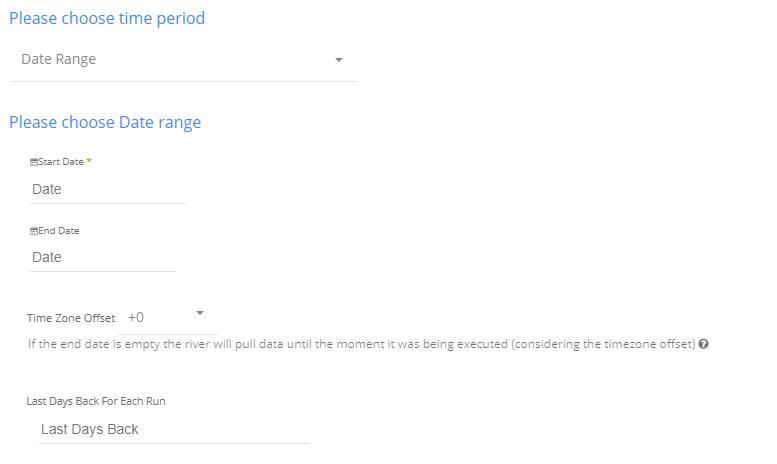 Select the type of time period of the report.
Select the type of time period of the report.
It can be a custom date range (as described in the picture above) or a defined time period shown in the pop-up list (for example Yesterday, last week etc.)
Instructions if selecting 'Date Range':
1. Select the start date and end date.
2. Leave the end date empty in order to pull data until the moment
the river runs.
3. After each run of the river, the start date will be updated automatically with the end date, and the end date will be updated with the empty value. This enables the next run to pull data from the end of the previous run.
4. Select the time zone offset. It will be relevant only if the end date is empty in order to find the moment of the river’s run according to the time zone.
5. Days back - use this input to tell Rivery to pull data from a given number of days back before the given start date.
6. The Start Date won't be advanced if a River run is unsuccessful.
If you don't want this default setting, click More Options and check the box to advance the start date even if the River run is unsuccessful (Not recommended).

Instructions if selecting any other value:
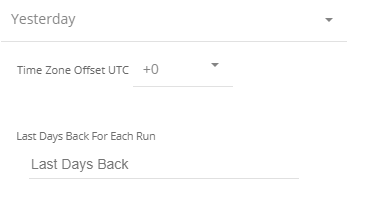
Select the timezone offset in order to send the correct dates that consider that offset.
Activity Logs
The Activity Logs offer an inside perspective of the processes taking place in Jira river.
Additional features in the Issues report
Problem updating schema with all custom fields
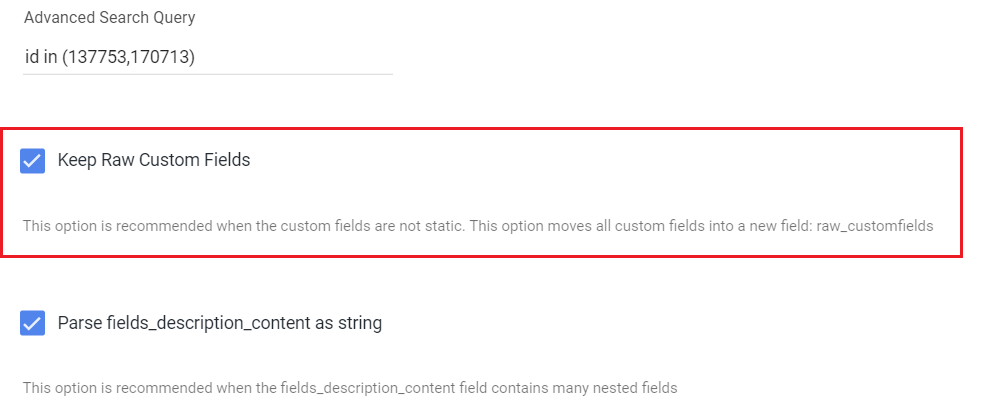
If you encounter scenarios where there are frequent alterations within your custom fields and you prefer to avoid the need for continual updates to the River's schema, The "Keep Raw Custom Fields" checkbox option comes into play.
This option enables you to maintain the original custom fields in the form of a JSON string. Consequently, all your custom fields, regardless of whether they are older or newly introduced, will be encompassed within the River's mapping, specifically within the "raw_customfields" field.
Issues with a complex field
If you experienced problem running the Issues report with one of the following errors:

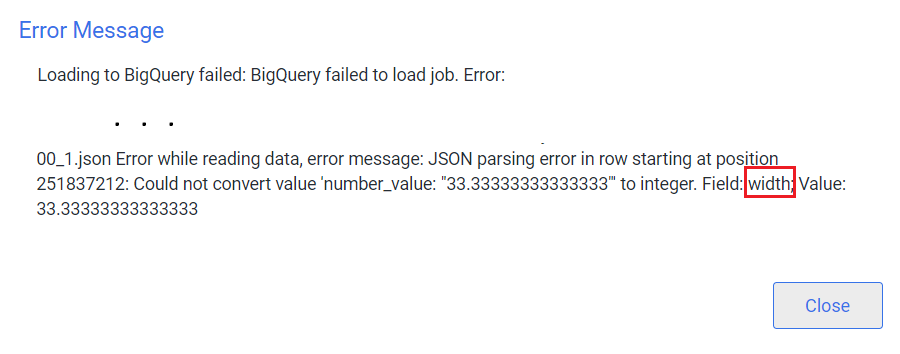
Please try checking this checkbox:
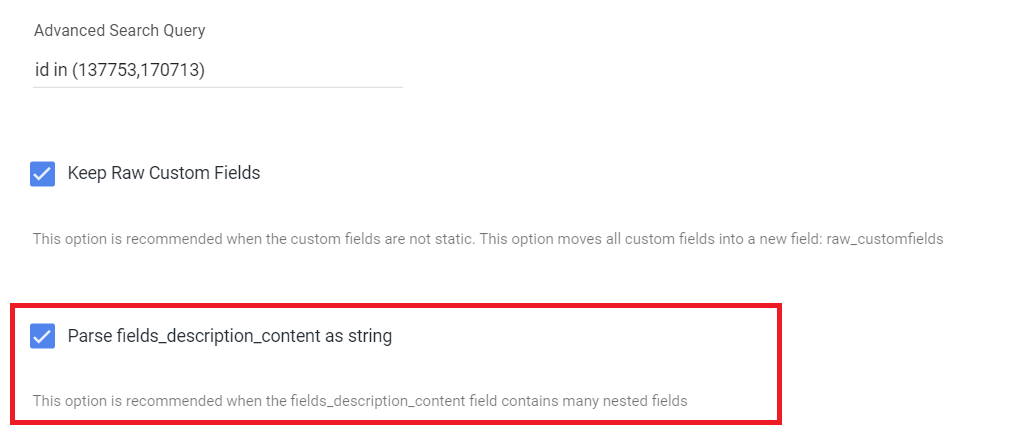
- By checking it, the field 'fields_description_content' will be a JSON string instead of a complex record field. This enables alternative datatypes in attribute fields (width/length), such as float/int types.
- Afterwards, please clear the mapping and press automapping again to catch the new field's data type.
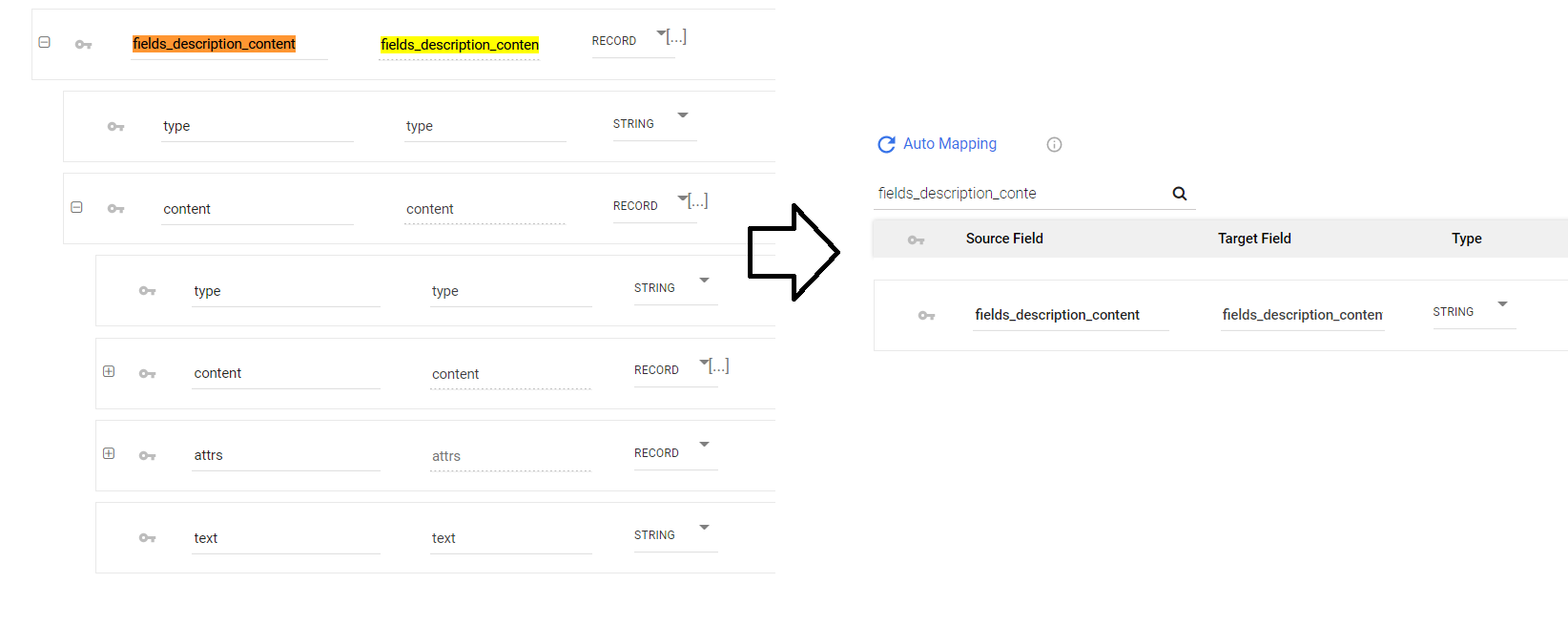
- Run the river.
Was this article helpful?