Salesforce Walkthrough
- 8 Minutes to read
- Print
- DarkLight
- PDF
Salesforce Walkthrough
- 8 Minutes to read
- Print
- DarkLight
- PDF
Article summary
Did you find this summary helpful?
Thank you for your feedback!
Salesforce Data into a Target
Using Rivery, you can pull data from Salesforce and send that data into your target database.
First, select 'Create New River' from the top right of the Rivery screen.
Choose 'Data Source to Target' as your river type.
In the 'General Info' tab, name your river and give it a description. Next, navigate to the 'Source' tab.
Find Salesforce in the list of data sources and select it:

Define a Salesforce Connection (this will be the connection created earlier in the process).
If you do not yet have a Salesforce connection in your Rivery account, you can create a new connection here by clicking 'Create New Connection.'
Pulling data from Salesforce
- Salesforce data organized in tables called entities.
- The entities can be regular Salesforce entities or custom ones.
- It is possible to pull all the data from a given table or only part of it using a filter according to some incremental field. For example: in order to pull the accounts that were created since 1.1.17, we'll pull the data according to the field " createdDate " and only when its value is later than 1.1.17.
Bulk, SOQL, and Metadata
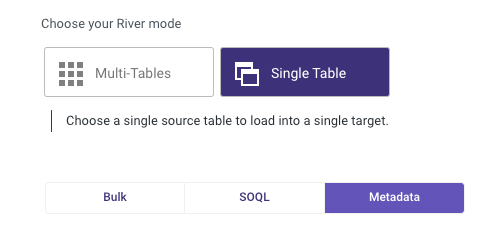
There are 3 ways to extract data from Salesforce with Rivery.
Bulk API - The new and preferred way to extract large sets of data from Salesforce, has a limitation of 10,000 batches in a 24 hours sliding window.
SOAP API/SOQL - The previous method utilizing the SOAP API, this method tends to be slower than the Bulk API.
Metadata is a report which allows extracting metadata info on an entity or several entities. Each row from a metadata report is the definition of a field from the selected entities, the pickup values field holds the naming conventions between the API and the UI for the closed list pickup values.
The metadata report is especially useful when comparing API to UI naming conventions.
Additional Features for Bulk API Mode
The Bulk API has an additional feature available to extract the method "all" only which is called pk chunking.

PK chunking is an automatic primary key chunking that splits bulk queries on very large tables into chunks based on the record IDs, or primary keys, of the queried records.
Supported objects:
Account, Campaign, CampaignMember, Case, CaseHistory, Contact, Event, EventRelation, Lead, LoginHistory, Opportunity, Task, User, and custom objects.
A custom object is any object which ends with a _c
The available range for pk chunking is between 100,000 and 250,000 records per chunk.
PK chunking significantly improves the extraction of large data sets.
Bulk API limitations
Batches for data loads can consist of a single file that is no larger than 10 MB.
A batch can contain a maximum of 10,000 records.
A batch can contain a maximum of 10,000,000 characters for all the data in a batch.
A field can contain a maximum of 32,000 characters.
10,000 batches in 24 hours sliding window limitation.
Configuring a Salesforce River
Choose your River mode.
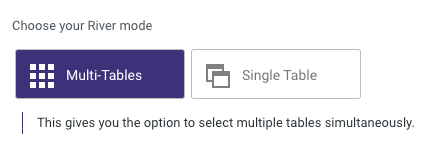
- Multi-Tables: Load multiple tables (entities) simultaneously from Salesforce to your target.
- Single : Choose a single table (entity) to load into a single target.
Multi-Table Mode
Load multiple tables simultaneously from Salesforce to your target.

Extraction API
After selecting the extract API, the metadata in the mapping tab will be pulled according to your selection.
Please note that when switching between these options, the metadata of tables and columns in the mapping tab will be updated accordingly.
Auto-Detect New Fields in Each Run
By default, Rivery will update the extracted tables metadata before each run execution. New fields will be added automatically when pulling the data by the river.
Disabling this option will make the river run according to its saved metadata without updating it before executing the data. You can track metadata updates manually by clicking the Reload Metadata in the mapping tab (and saving the river afterward).
When new fields are added to the column mapping, existing target names/data types for mappings will be kept.
Mapping
In the Mapping tab, select the entities to load.
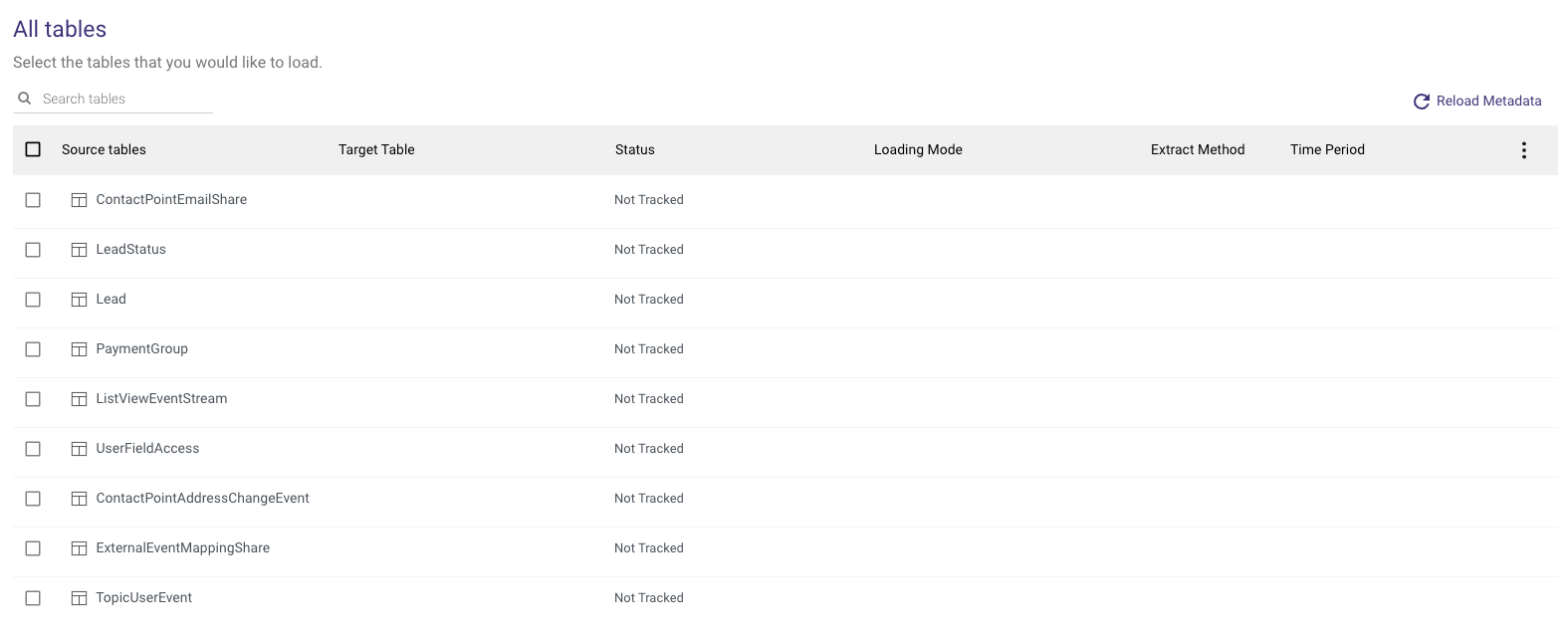
Click the 'Edit' button on the right to edit individual entities' table settings.
Table Settings in a Multi-Table Mode
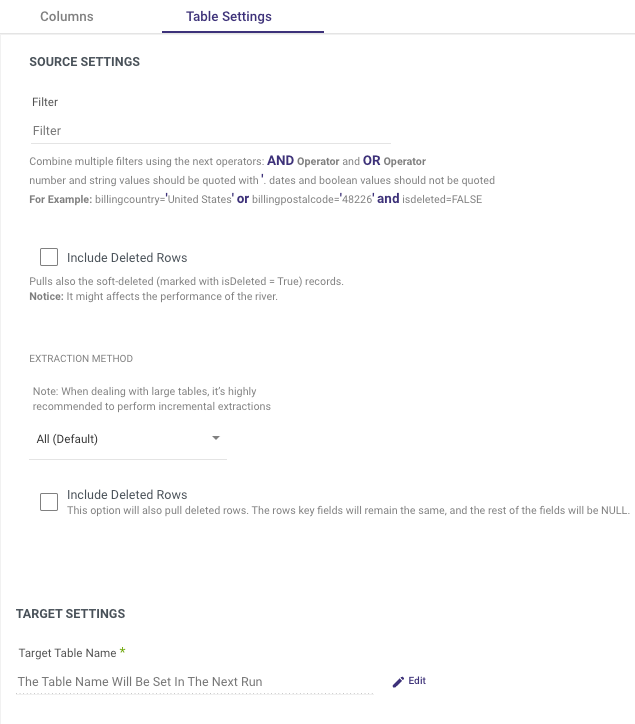
On the 'Table Settings' tab you are able to edit the following:
Change the loading mode
Change the extraction method. If 'Incremental' is selected, you can then define which field will be used to define the increment.
Filter by an expression that will be used as a WHERE clause to fetch the selected data from the table.
Set PK Chunking for entities that allow primary key chunking.
Enable the option to include deleted rows in the extracted data.
Filter
Add any filter to act as a WHERE clause for pulling the data.

- Important:
We recommend to pull all the data without filters from Salesforce, and then filtering it using the Logic in Rivery. If decided to use the filters in Salesforce it is important to keep the syntax of the filters as it supported in Salesforce.
Combine multiple filters using the next operators: AND Operator and OR Operator
number and string values should be quoted as “ ' “.
dates and boolean values should not be quoted.
For Example:
Include Deleted Rows
This option will include the rows that were marked as deleted by the soft-delete mechanism of SalesForce. In this case, the isDeleted field's value will be True.
Notice: checking this option can affect the performance of the river.
Legacy River Mode
This River mode allows for a load of a single source table into a single target table.
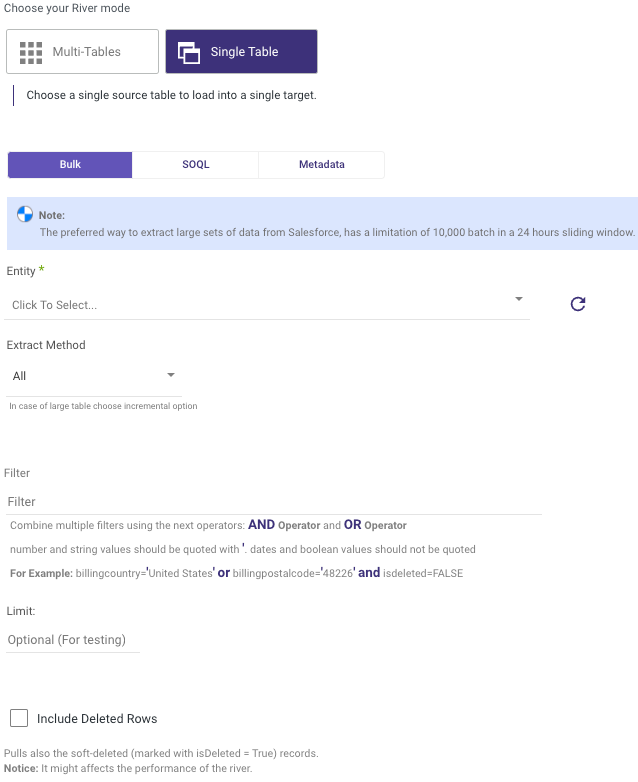
Entity
Select the entity to pull the data for. Click on the input in order to get a list of all available entities in the given Salesforce account.

Extract Method:
Using Rivery, you can pull your data incrementally or pull the entirety of the data that exists in the table:
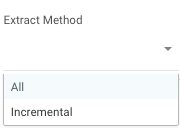
- All: Fetch all data in the table using Chunks.
- Incremental: Gives you the option to run over a column in a table.
- Incremental field - Click on the input in order to get a list of all available columns in the selected entity.

This field must be a field with incremental values that can be filtered, such as dates, running numbers etc.
- Incremental type - After selecting the incremental field, select what kind of increment the selected incremental field is. It can be either date, timestamp, or running number.

- Time period - select the time range of data to pull from the selected entity.
Note: Rivery will manage the increments over the runs using the Maximum value in the data. This means you will always get the entire data since the last run, which prevents data holes. You just need to configure your river once.
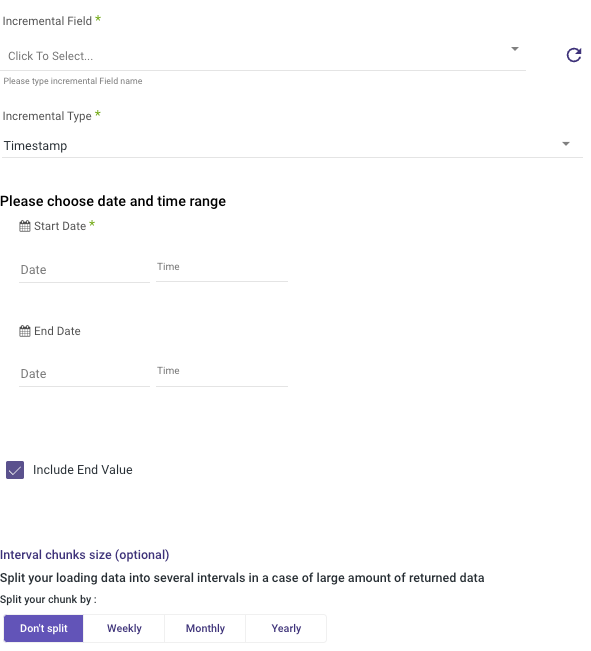
1. Select the start date - Rivery will pull only data with the selected incremental field later than this start date.
2. Select the end date - Rivery will pull only data from the selected incremental field earlier than this start date. Leave the end date field empty in order to pull data until the moment the river runs.
3. After the river runs, the start date will be updated with the value of the end date and the end date will be updated with an empty value. So the next run will extract data later than the current end date.
4. Include End Value - Check it in order to include records with the end value in the results. If this input is not checked, then those records will be pulled in the next run.
Please note:
The Start Date won't be advanced if a River run is unsuccessful.
If you don't want this default setting, click More Options and check the box to advance the start date even if the River run is unsuccessful (Not recommended).

Interval Chunk Size
Use this input when trying to pull long periods.
Salesforce might have difficulties returning very large amounts of data, so splitting the requests to smaller ones might be helpful. Doing so will take the given start date and end date and will calculate the smaller period of time to pull the data for.
Important: The results will be totally equal when pulling data without interval chunks and with any selected interval chunks. This is only for improving the performance of the connection against the Salesforce API.
Important: If using the interval chunks, it is important to pull the date column in order to identify the time of each record in the results.
Mapping Attribute
Select which fields to pull from the selected entity.

1. Click on the “Auto Mapping” button in order to execute the mapping process
2. Rivery will sample the data from Salesforce and will present the fields in the given table (regular fields and custom fields). Each field has its own type. This type cannot be changed.
3. It is possible to search for a specific field in the table and then remove it.
4. Remove a field or multiple fields - mark each field by clicking on the button left to the field and click on the trash button in the right-top corner of the mapping table.
5. In order to clear all the fields in the mapping table- click on the V sign button in the left-top corner to mark all the fields in the table and then click on the trash-can button.
6. Any field in the mapping table will be pulled from the entity table. In case there are unnecessary fields it is recommended to remove them from the mapping table in order to improve the API performance.
7. The fields in this mapping table will be copied to the target attributes mapping (in step 3 of the river) when clicking on the Auto Mapping in step 3 of the river.
Non-queryable Objects
"Queryable objects" is a term used to describe a feature of Salesforce objects that allows for data to be retrieved through the Salesforce API via queries. Although the majority of standard and custom objects in Salesforce are queryable by default, there are certain exceptions due to security considerations.
Rivery will not display the non-queryable objects in your Salesforce object list. The following is a list of such non-queryable objects.
Activity Logs
The Activity Logs offer an inside perspective of the processes taking place in Salesforce river.
Was this article helpful?